프로젝트
[Project] Interregional Correlation Analysis of COVID-19 Confirmed Cases using LSTM: linear and non-linear correlation analysis
- -
상관 관계 분석(correlation analysis)을 함에 있어서 다양한 기법이 있습니다. 그 중 대표적인 방법은 변수 간의 피어슨 상관 계수(Pearson correlation coefficient)를 알아보는 것입니다.
피어슨 상관 계수를 통하여 -1 ~ 1 까지의 수치를 얻어내고 변수들 간의 어느정도 관계가 있는지 양의 상관 관계, 음의 상관 관계를 얻어낼 수 있습니다. 피어슨 상관 계수를 구하는 것은 선형 상관 관계(linear correlation)를 구하는 것입니다. 그치만, 피어슨 상관 계수를 구한다 해서 변수 간의 상관 관계를 완벽하게 알 수 있는 것이 아닙니다. 피어슨 상관 계수에 반영되지 않는 부분도 여러가지 있을 것입니다.
이 피어슨 상관 계수가 포착하지 못하는 부분을 알아내기 위하여 딥러닝 기법을 이용하고자 합니다. 딥러닝 기법은 모델을 구성하는 layer들에 활성화 함수를 적용을 시켜줍니다. 이 활성화 함수는 대부분 비선형 함수이기 때문에 결과적으로 비선형성을 반영한 결과를 도출하게 되어 다양한 의미를 내포한다는 것이 딥러닝의 가장 큰 매력이자 장점입니다. 저는 이런 비선형성을 띄는 딥러닝 모델의 결과를 이용하여 변수들 간의 상관 관계를 분석해 보면 어떨까라는 생각을 하게 되었습니다. 선형성을 띄는 피어슨 상관 관계 기법과 비선형성을 띄는 딥러닝 상관 관계 기법을 비교해보면 의미 있는 결과물을 도출해 낼 수 있을 것 같았습니다.
상관 관계 분석 대상을 대한민국 지역별 코로나 바이러스 확진자 수로 하였습니다. 이는 상당히 의미가 있을 것으로 보입니다. 지역 간의 코로나 확진 자 수의 상관 관계를 분석해 본다면, 코로나 바이러스 대응을 조금 더 유연하게 할 수 있을 것으로 기대됩니다. 또한, 딥러닝 모델 중 시계열 데이터에 자주 적용되는 LSTM 모델을 사용하기로 했습니다.
GitHub - kangmincho1/Interregional-Correlation-Analysis-of-Conronavirus-Confirmed-Cases-using-LSTM
Contribute to kangmincho1/Interregional-Correlation-Analysis-of-Conronavirus-Confirmed-Cases-using-LSTM development by creating an account on GitHub.
github.com
Dataset
coronaboard에서 제공하는 한국 일일 누적 확진자 및 지역별 일일 누적 확진자 수 데이터
데이터 기간: 2020/2/17 ~ 2021/6/9, 총 479일
GitHub - jooeungen/coronaboard_kr: 코로나19 한국 발생 현황
코로나19 한국 발생 현황. Contribute to jooeungen/coronaboard_kr development by creating an account on GitHub.
github.com
Data preprocessing
기존 데이터는 지역별 데이터가 전부 섞여있는 형태이기 때문에 이를 분리시켜 주는 작업이 필요했습니다.


또한, 필요로하는 데이터는 일별확진자 수 데이터이지만, 얻어진 데이터는 일별 누적 확진자 수에 대한 데이터이기 대문에, 이를 일별 확진자 수 데이터로 전처리 해줘야 할 필요가 있었습니다.

데이터 셋의 구성은 feature data와 target data를 하나의 dataset으로 묶어 구성을 했습니다.
feature data 셋과 target data의 상관 관계도 볼 수 있고, 이를 LSTM 모델에 넣어 학습을 시킬 수도 있는 데이터 셋입니다.
학습 효과를 높여주기 위하여 minmaxscaling을 진행했습니다.
최종적으로 사용할 데이터를 얻게 되었습니다.
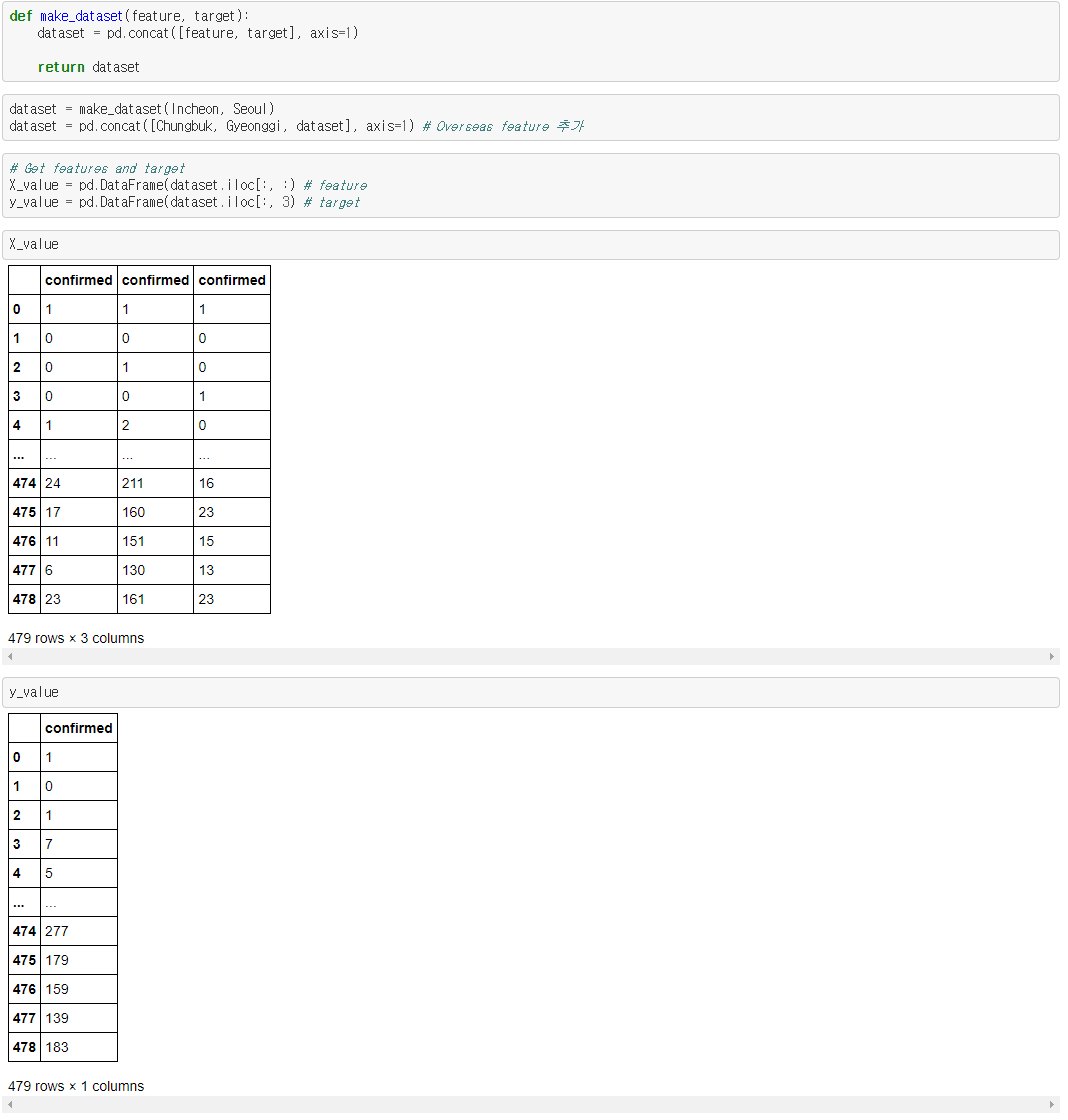
대한민국 지역별 일일 확진자 수를 matplolib을 이용하여 플롯을 그려봤습니다.
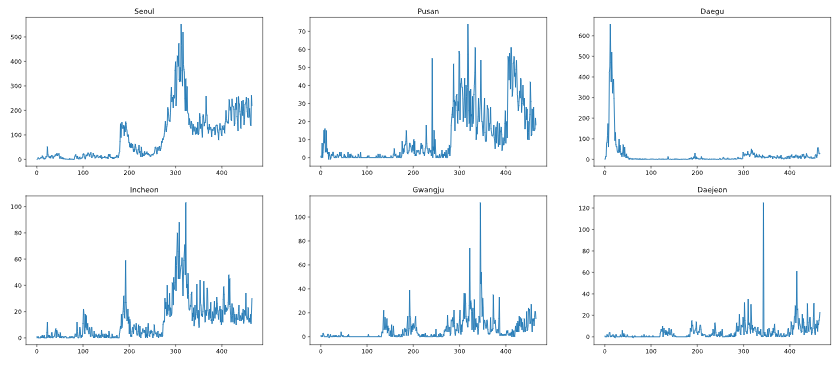
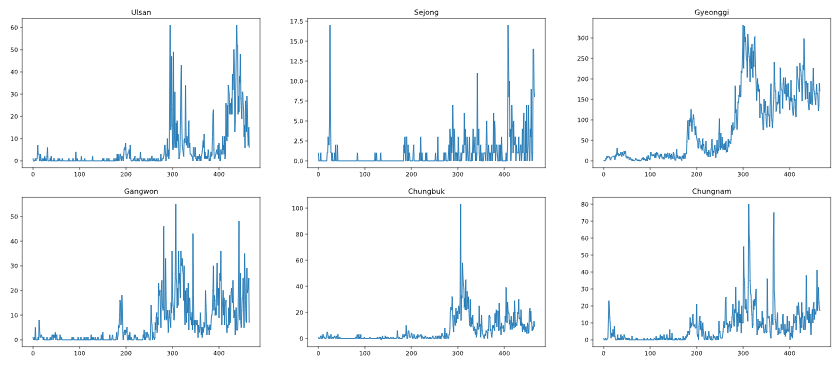
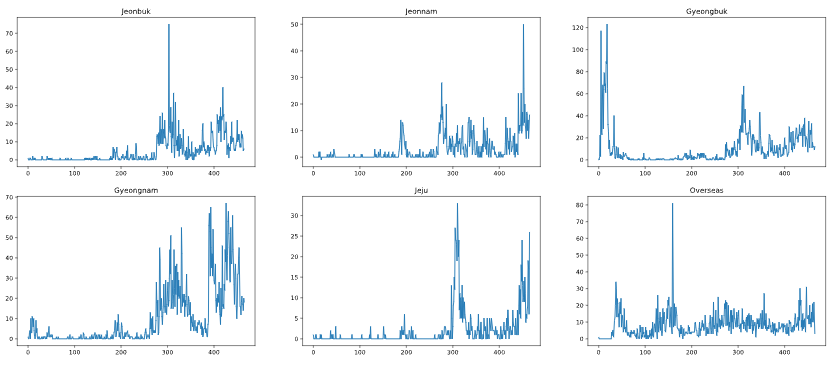
Method
이렇게 얻어진 데이터를 이용해서 이 프로젝트가 제시하는 방법을 소개하겠습니다.
우선 딥러닝 모델을 적용하기 전에, 피어슨 상관 계수를 데이터에 적용시켜 보았습니다. 피어슨 상관 계수에 대해서 간략하게 짚고 넘어가겠습니다.
Pearson correlation coefficient
통계학에서 , 피어슨 상관 계수(Pearson Correlation Coefficient, PCC)란 두 변수 X 와 Y 간의 선형 상관 관계를 계량화한 수치입니다. 피어슨 상관 계수는 코시-슈바르츠 부등식에 의해 +1과 -1 사이의 값을 가지며, +1은 완벽한 양의 선형 상관 관계, 0은 선형 상관 관계 없음, -1은 완벽한 음의 선형 상관 관계를 의미합니다. 일반적으로 상관 관계는 피어슨 상관 관계를 의미하는 상관 계수입니다.
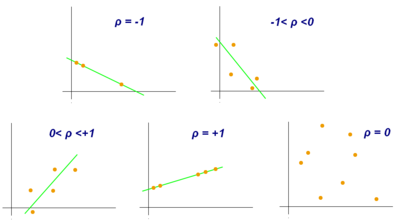
먼저, 한국 지역별 일일 코로나 확진자 수에 대한 피어슨 상관 계수를 구하기 위해 데이터 셋을 구성합니다.

역시 이 데이터 셋에 minmaxscaling을 적용시킵니다.
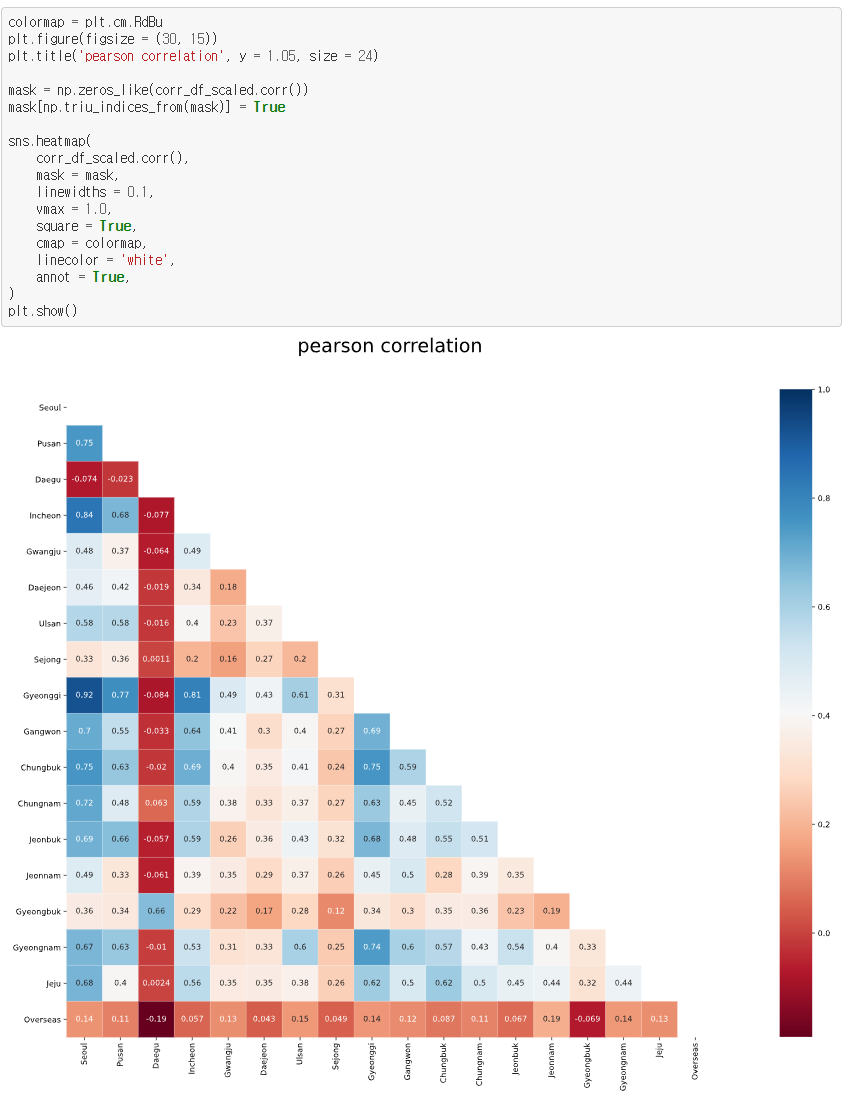
피어슨 상관 계수를 확인합니다.
앞서 설명했듯이, 1에 가까울수록 양의 상관 관계가, -1에 가까울수록 음의 상관관계가 높은 것입니다. 이 plot에서는 파란색일수록 1에 가까운 것이며, 빨간색일수록 -1에 가까운 것입니다. 이를 보시면, 대구지역이 다른 지역과의 상관 관계가 나쁜 것을 확인 할 수 있습니다. -1에 가까운 것도 아니고, 0에 가까워 음의 상관관계가 있다고 보기도 어렵습니다. 그 이유를 생각해보니, 대한민국 코로나 발생 초창기에 대구, 경북 지역에서 대량의 코로나 확진자 수가 발생했었는데, 이 기간의 데이터가 너무 큰 이상치(outlier) 데이터여서 이 기간의 데이터가 크게 영향을 미친 것 같습니다.
위의 그림은 한 눈에 파악하기 힘드니, 따로 피어슨 상관 계수의 순위를 나타내보았습니다.
이는 서울을 기준으로 다른 지역간의 피어슨 상관계수 순위를 나타낸 것입니다.
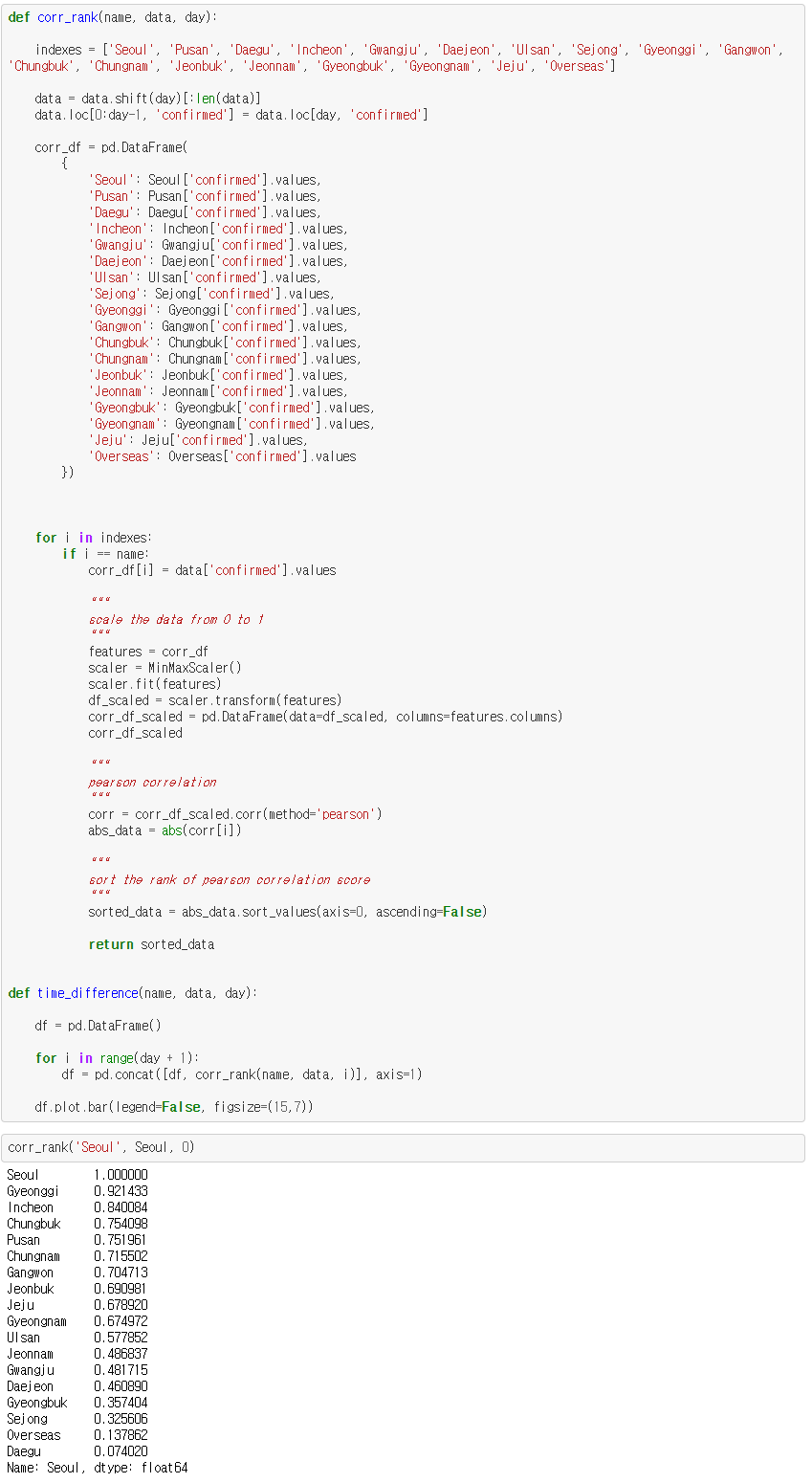
위 순위를 plot으로 그려보았습니다.
피어슨 상관 계수를 적용시켜본 결과, 서울 기준으로 경기, 인천, 충북, 부산, 충남, 강원, 전북, 제주, 경남, 울산, 전남, 광주, 대전, 세종, 해외 입국자 순으로 나타나는 것을 볼 수 있습니다.
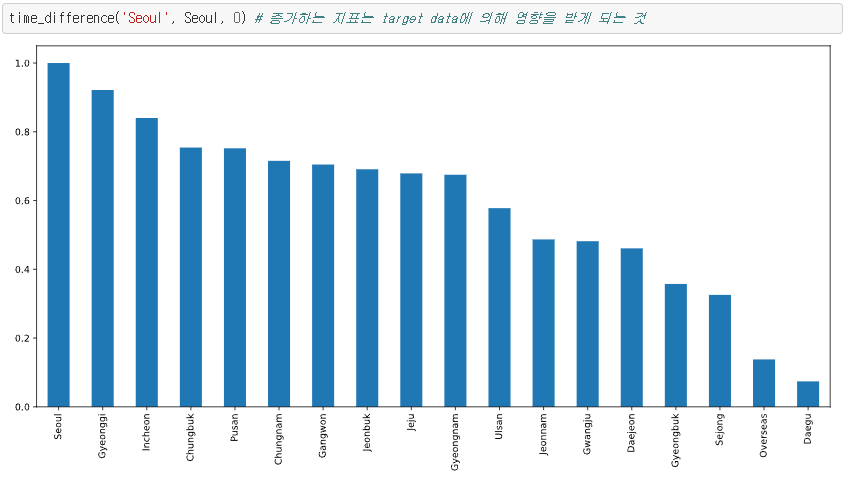
지금부터 이 프로젝트의 핵심이라고 볼 수 있는 부분입니다. 여태까지 진행했던 피어슨 상관 관계 분석법은 선형, 즉 linear한 상관 관계 분석법입니다.
따라서 선형적으로만 상관관계를 분석하기 때문에, 피어슨 상관 관계만으로 지역간의 확진자 수의 상관 관계를 전부 포함한다고 볼 수는 없습니다.
따라서 다각도로 상관관계를 분석해보면 어떨까라는 생각에서 딥러닝을 사용하게 됩니다.
딥러닝, 즉 뉴럴 네트워크는 비선형성을 띕니다. 뉴럴 네트워크의 layer 별로 달려있는 활성화 함수는 비선형 함수이기 때문에, 뉴럴 네트워크를 거쳐서 나온 결과물은 feature들의 비선형성을 학습하고 도출해 낸 결과입니다. 따라서 딥러닝의 이런 non-linear한 특성을 이용하여 피어슨 상관계수가 포착해 내지 못한 부분을 이 딥러닝을 활용하여 상관 관계 분석을 해보면 어떨까라는 생각을 해봤습니다.
코로나 일별 확진자 수 데이터는 시계열 데이터이기 때문에 시계열 데이터 예측에 주로 사용되는 LSTM(Long Short-Term Memory) 모델을 사용하기로 했습니다.
그러면, 어떻게 이 LSTM을 이용해서 지역별 상관관계 분석을 할 것인가인데요, LSTM을 이용해서 목표하는, 즉 target data의 확진자 수를 예측해보는데, 이를 학습할 데이터로 target data와 관계성을 보고 싶은 지역의 데이터를 input으로 넣어주는 겁니다.
이렇게 해서 나온 평가지표 지수를 가지고 상관 관계를 파악할 것입니다.
LSTM의 주 task를 예측이 아닌, 이를 통해 학습 되어진 결과의 평가지수의 점수를 가지고 얼마나 예측을 더 잘했느냐를 보는 것입니다. 이를 통해 input data와 target data의 관계성을 볼 수 있지 않을까 생각했습니다.
이는 LSTM을 이용한 상관 관계 분석 모델의 파이프라인입니다.
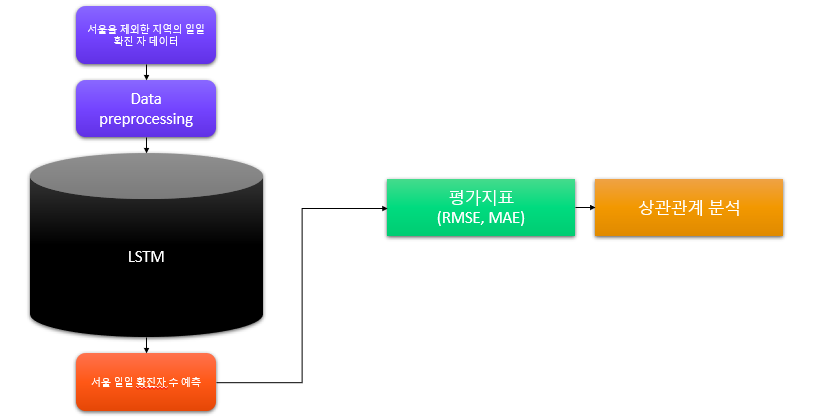
타겟 지역의 데이터와 타겟 지역과의 상관 관계를 알아볼 지역의 데이터를 학습데이터로 넣어줍니다.
일반적으로 주가 예측을 할 때, input data에도 target data의 과거 데이터를 넣어 주어 더욱 예측을 잘 할 수 있도록 합니다. 그러나 이 프로젝트는 예측이 주 목표가 아닌, 타겟 지역과 다른 지역의 상관 관계를 보는 것이 목적이기 때문에 input data는 오로지 타겟과의 상관 관계를 볼 데이터만 넣어주고 이에 대한 라벨링 데이터를 타겟 지역 데이터로 넣어주어 학습시켰습니다.
타겟 데이터의 예측은 하루로 설정했습니다. 이렇게 해서 나온 평가지표의 점수로 상관 관계 분석을 해봤습니다.
이때, 학습할 시퀀스(과거 데이터의 길이)를 10일, 20일, 30일로 다양하게 설정하여 한 지역이 타겟 지역 데이터에 대해서 며칠간 영향을 미치는지 알아보도록 했습니다. 이 입력 시퀀스를 달리 함으로써, 더욱 더 정교한 상관 관계 분석을 할 수 있었습니다.
training set과 testing set의 비율은 7:3으로 설정하였습니다.
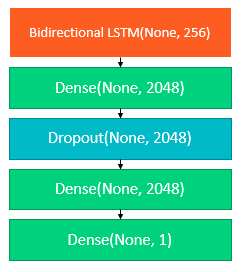
이 프로젝트에서 사용한 LSTM의 구조를 보겠습니다.
순환 신경망의 시계열 데이터의 직전 패턴 기반으로만 하습하는 경향을 보이는 한계를 해결하기 위하여, 데이터의 흐름의 역방향에 은닉계층이 추가되는 Bidirectional LSTM을 이용하여 모델을 구성했습니다.
Result
대한민국 수도 서울을 기준으로 다른 지역과의 상관 관계를 파악했습니다.
평가지표는 RMSE로 설정했습니다. MAE에 비해서 RMSE가 이상치(outlier)에 대해서 포착을 잘하므로 상관 관계를 파악하는데 MAE보다 적합해 보여서 이로 설정했습니다. 또한, RMSE 수치가 낮은 순으로 상관 관계가 높다고 판단했습니다.
입력 시퀀스를 10, 20, 30일로 바꿔가며 결과를 확인했습니다.
Sequence 10 days
서울 - 경기
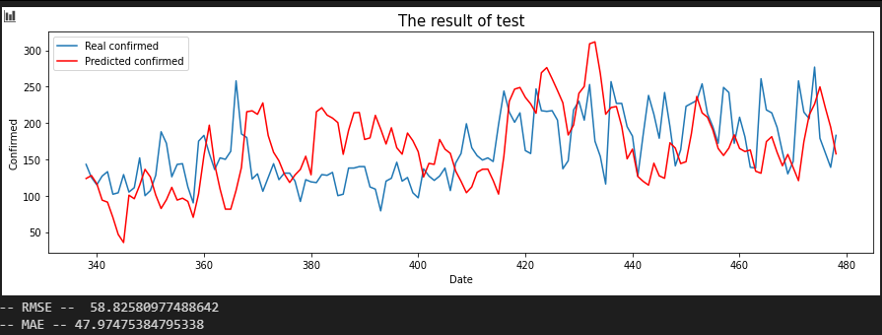
서울 - 충북
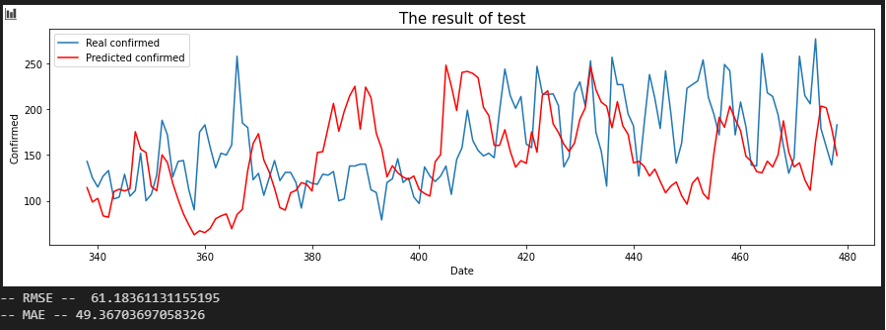
서울 - 대전
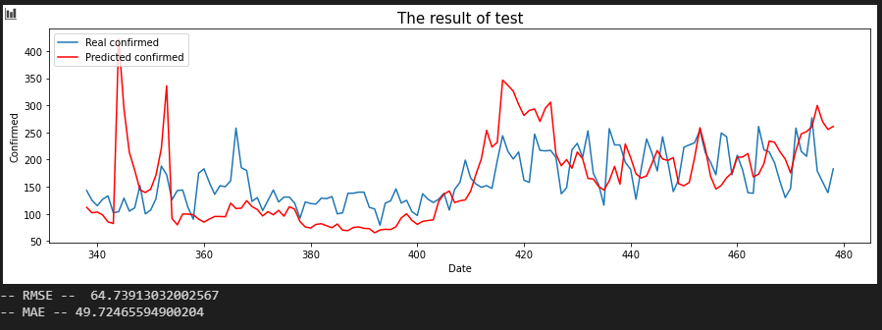
서울 - 세종
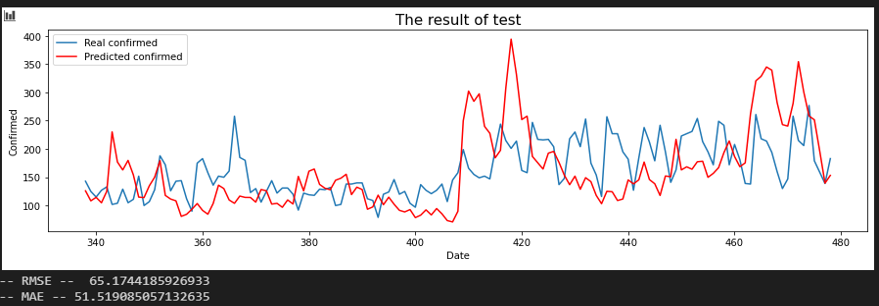
서울 - 강원
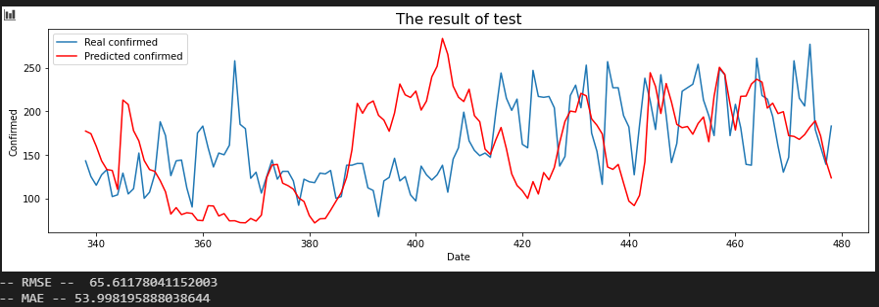
서울 - 인천
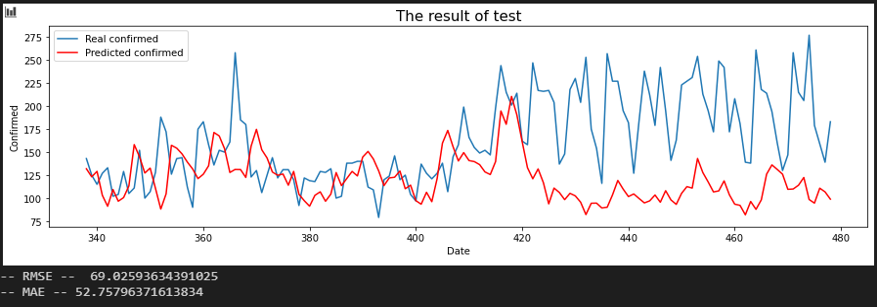
서울 - 부산
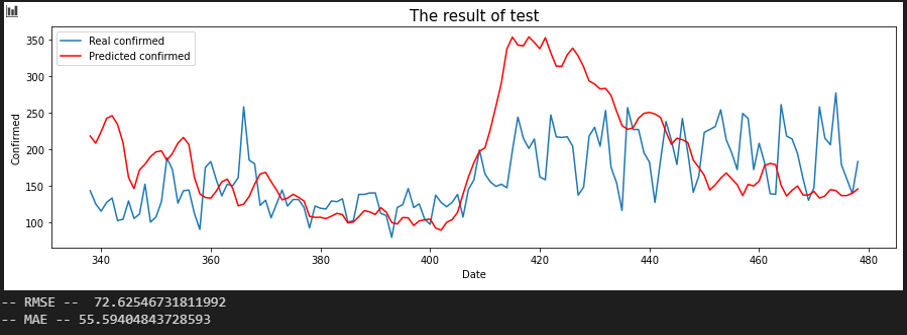
서울 - 전북
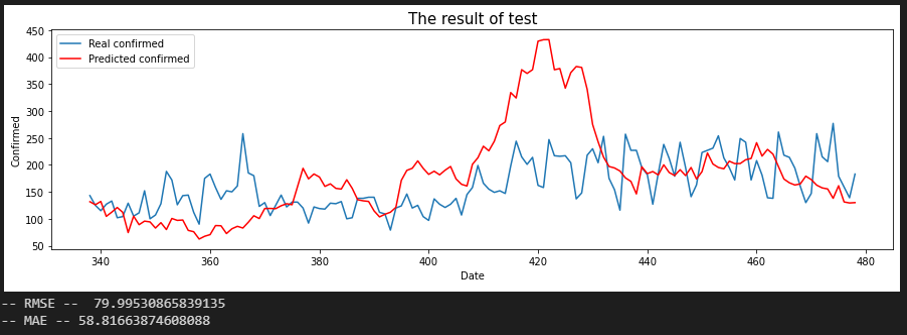
서울 - 해외 입국자
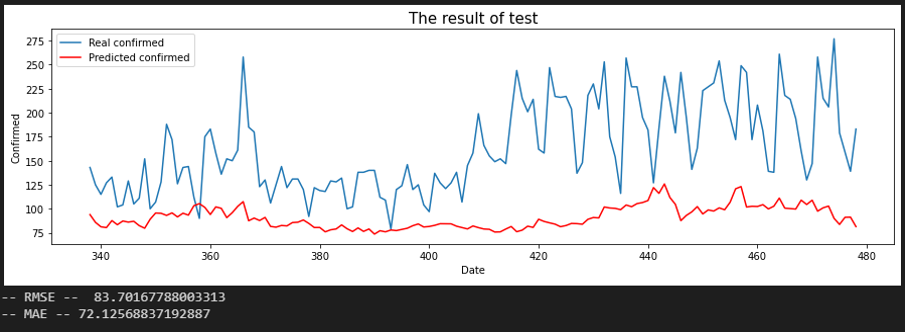
서울 - 제주
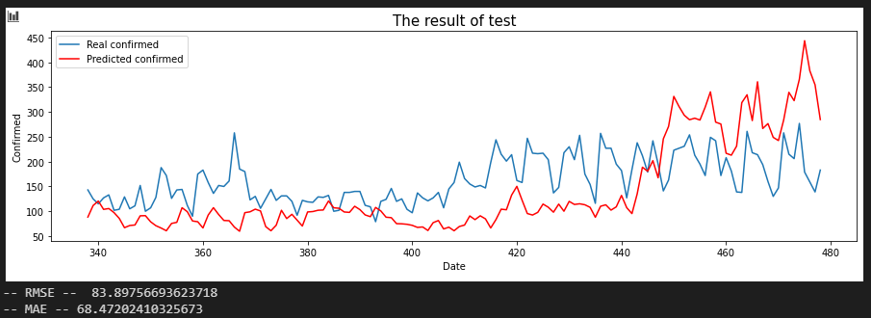
서울 - 충남
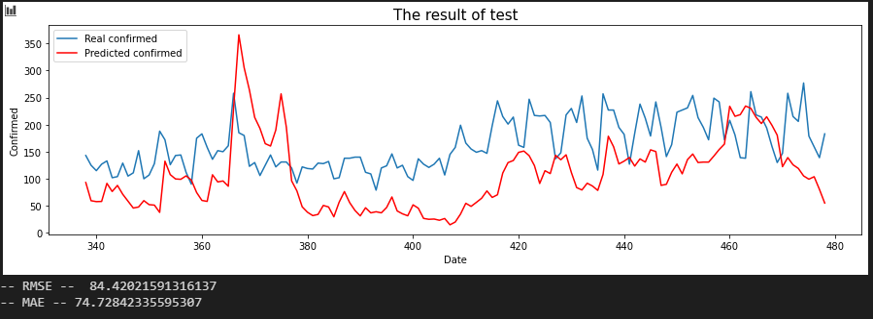
서울 - 전남
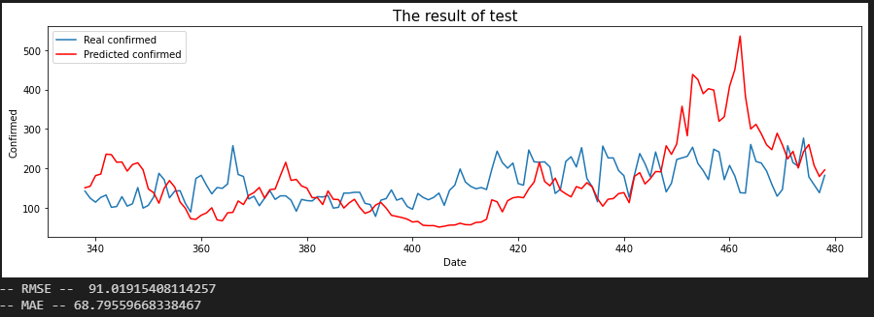
서울 - 경남
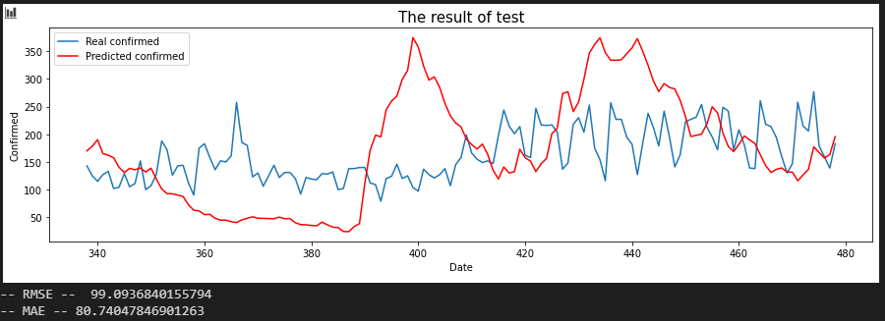
서울 - 광주
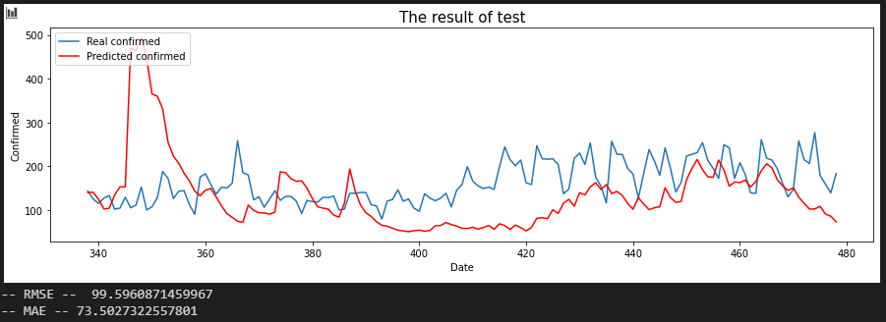
서울 - 울산
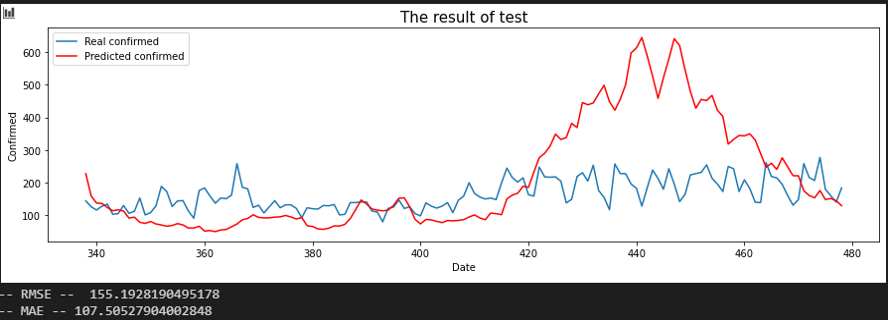
Sequence 20 days
서울 - 대전
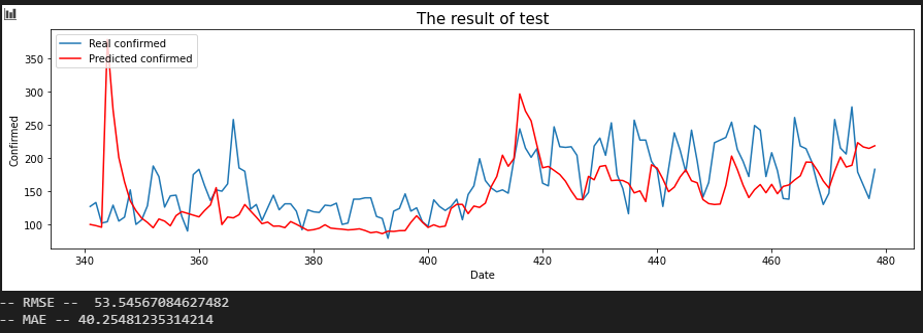
서울 - 세종
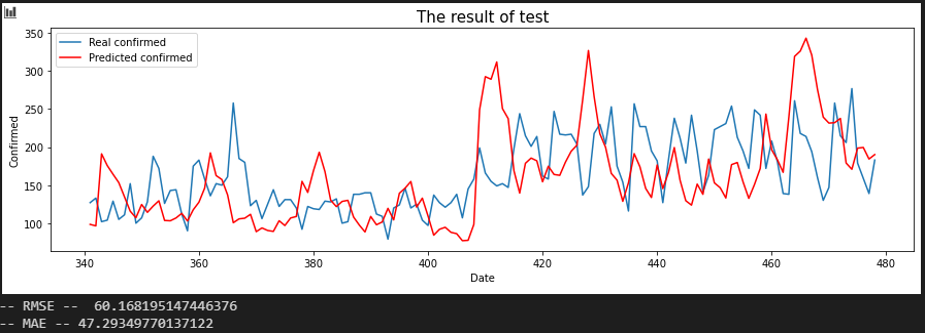
서울 - 충북
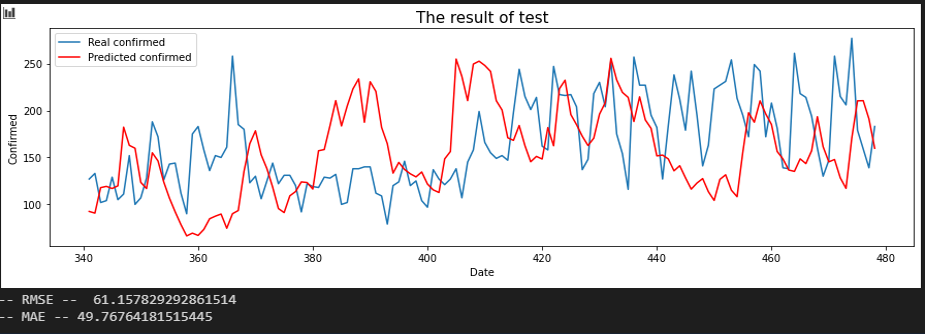
서울 - 경기
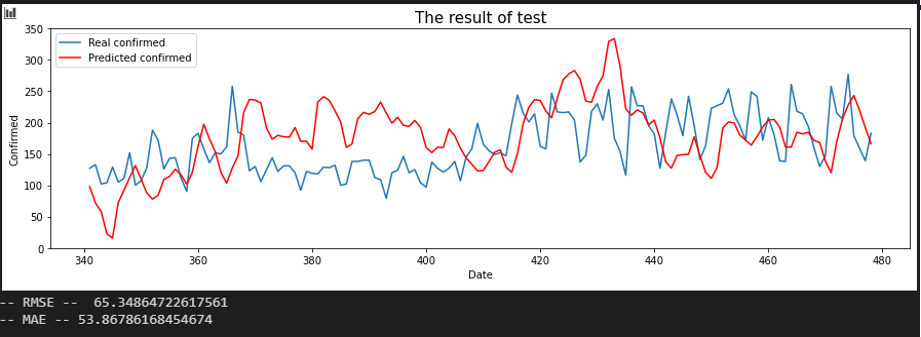
서울 - 강원
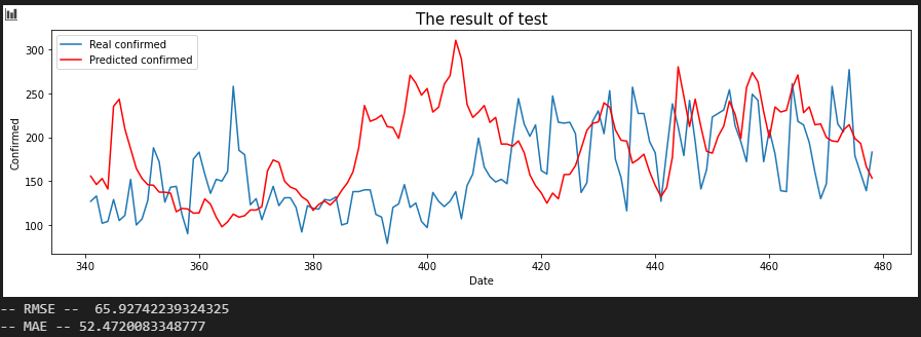
서울 - 충남
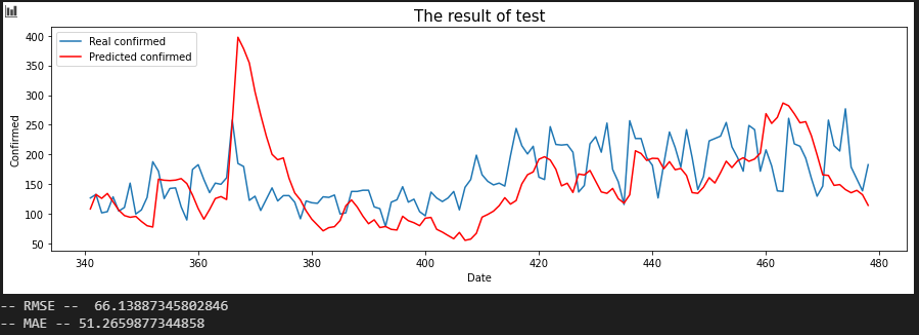
서울 - 인천
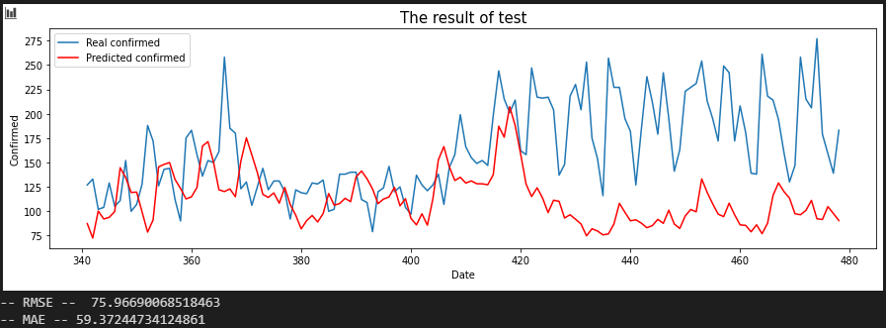
서울 - 전남
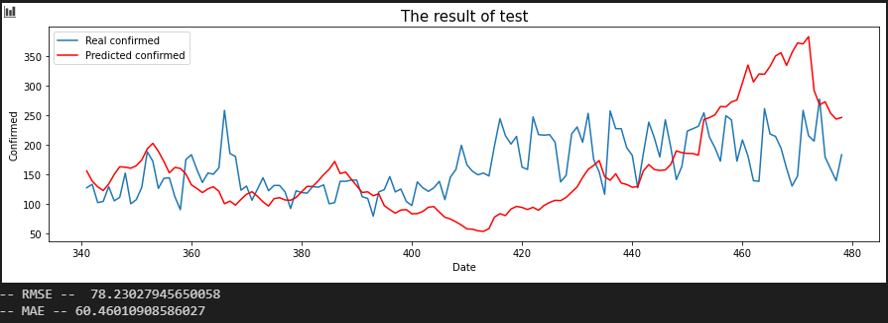
서울 - 전북
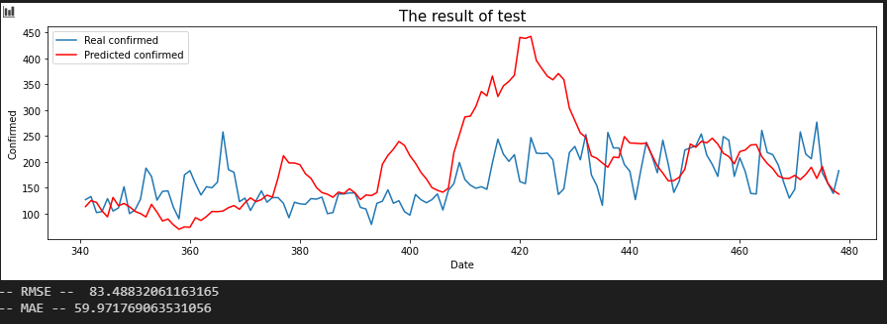
서울 - 해외 입국자
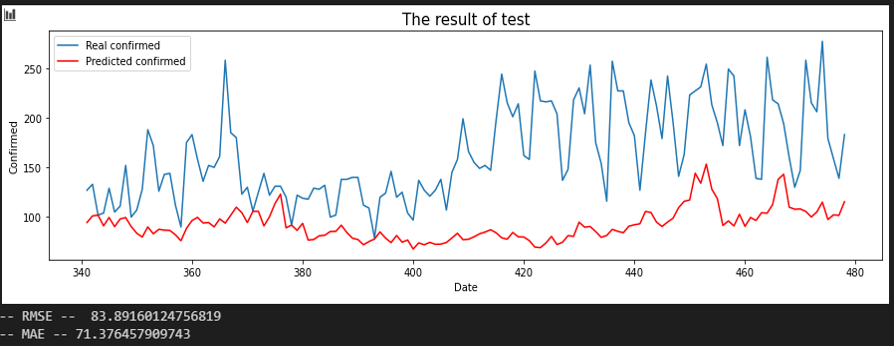
서울 - 제주
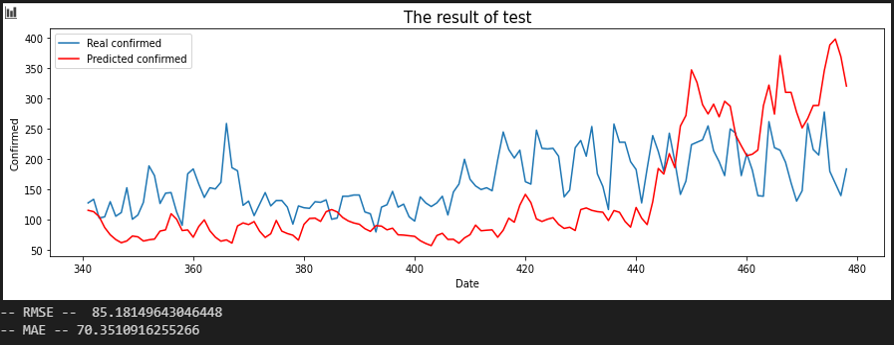
서울 - 부산
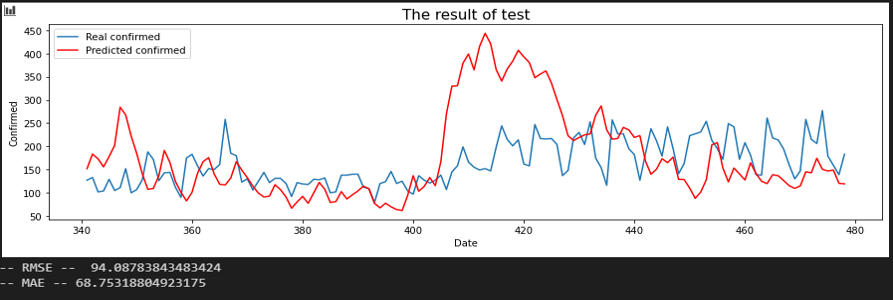
서울 - 광주
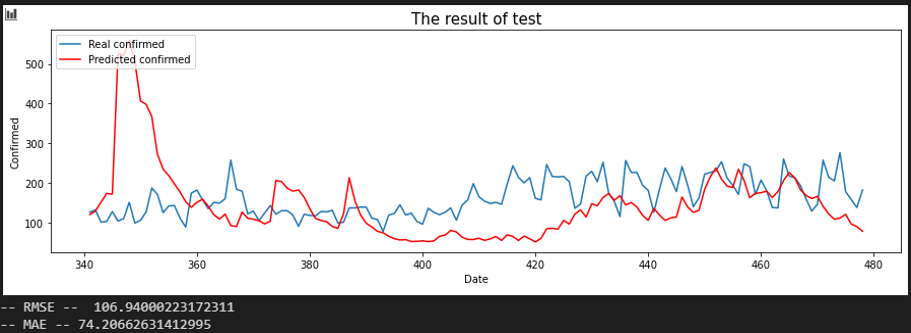
서울 - 경남
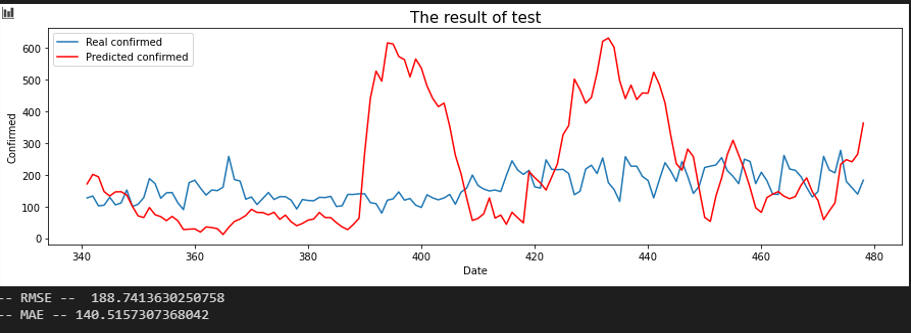
서울 - 울산
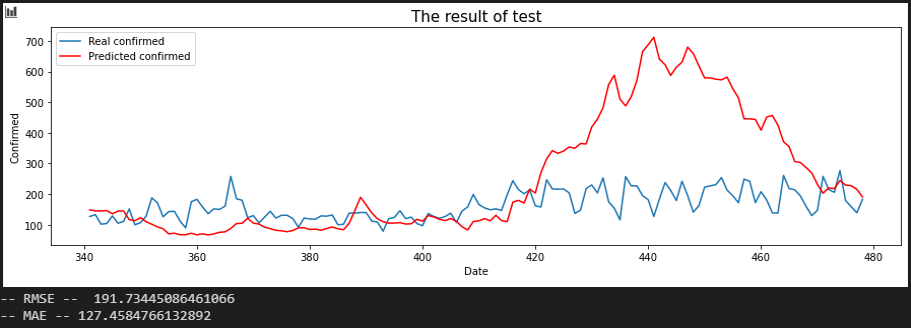
Sequence 30 days
서울 - 충북
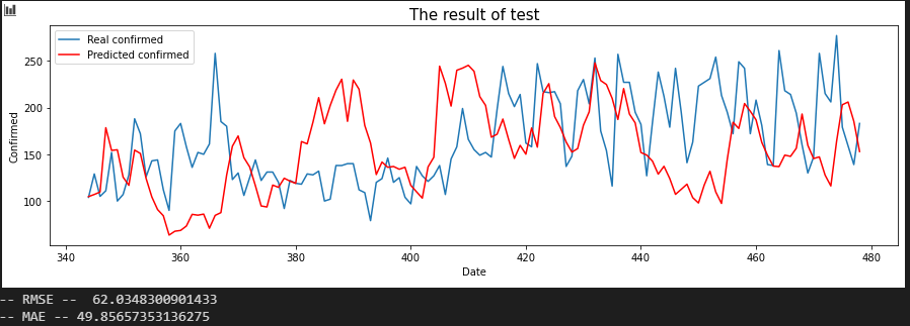
서울 - 강원
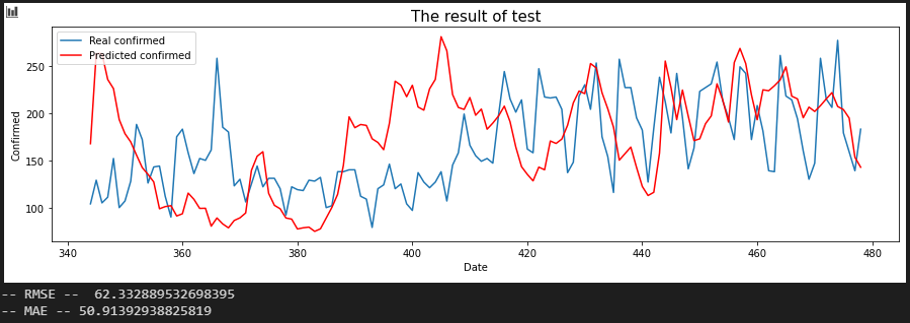
서울 - 충남
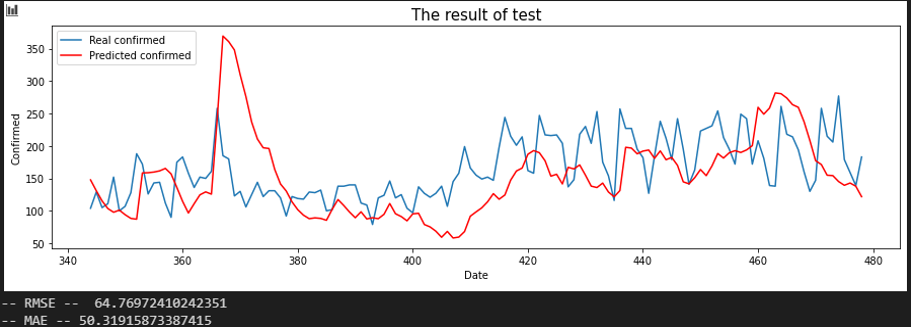
서울 - 경기
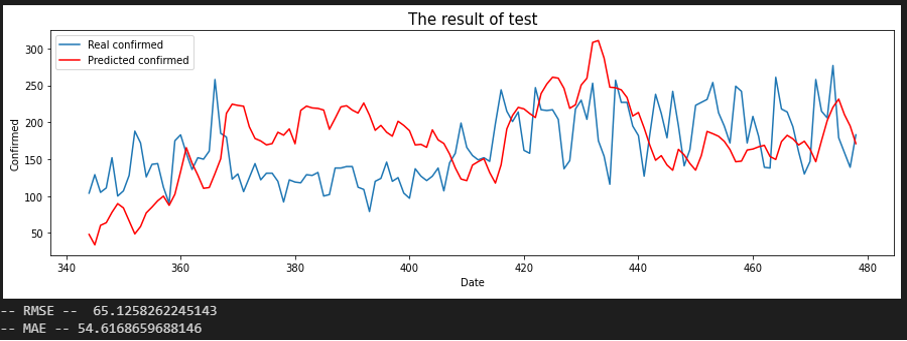
서울 - 인천
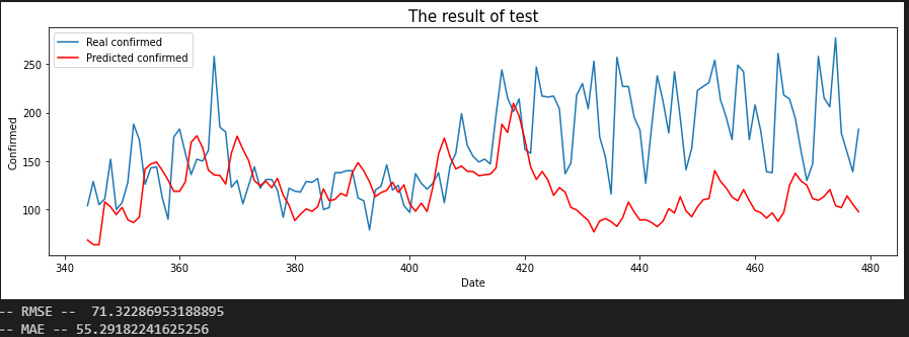
서울 - 제주
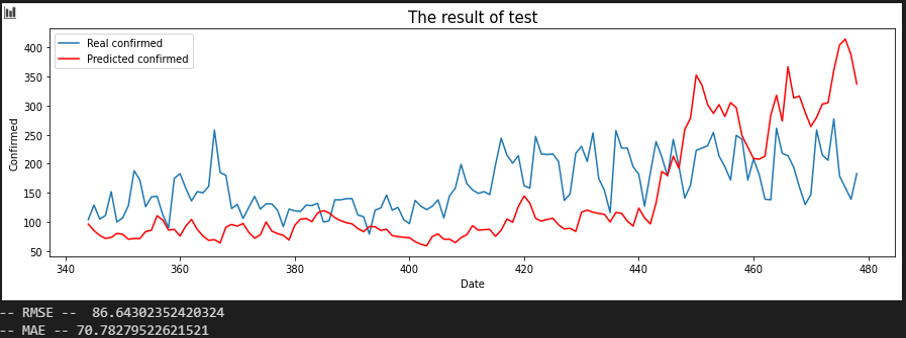
서울 - 전북
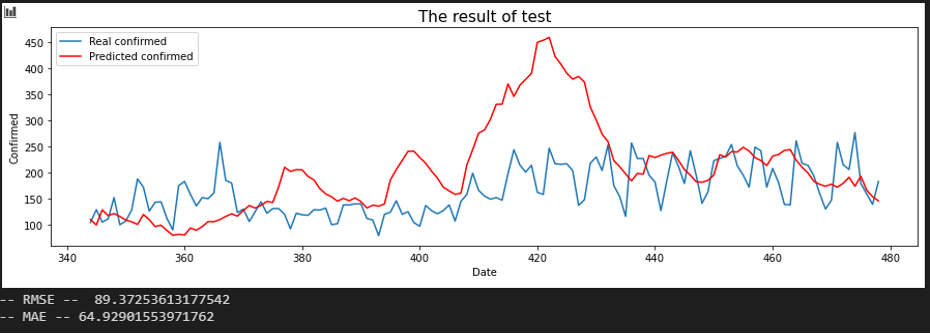
서울 - 대전
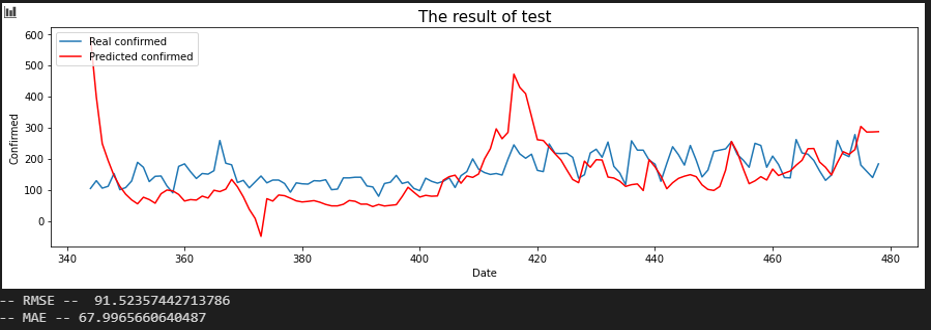
서울 - 해외 입국자
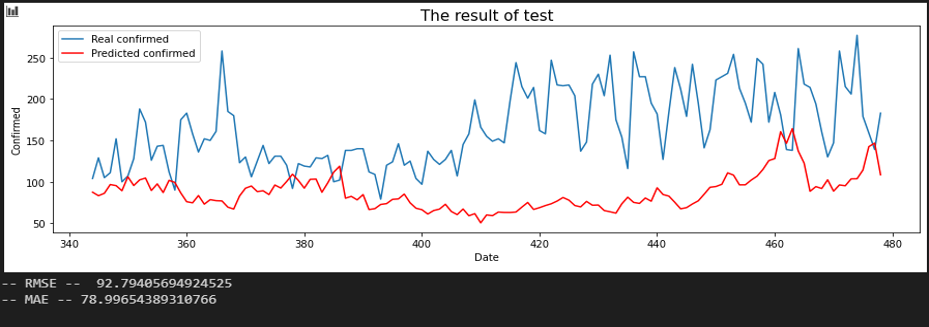
서울 - 부산
서울 - 전남
서울 - 광주
서울 - 세종
서울 - 경남
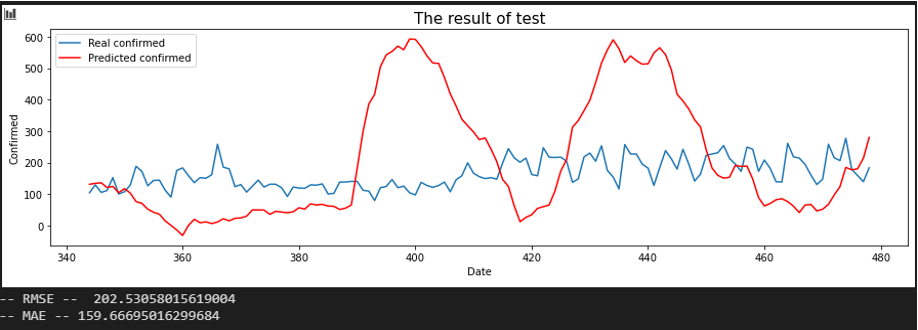
서울 - 울산
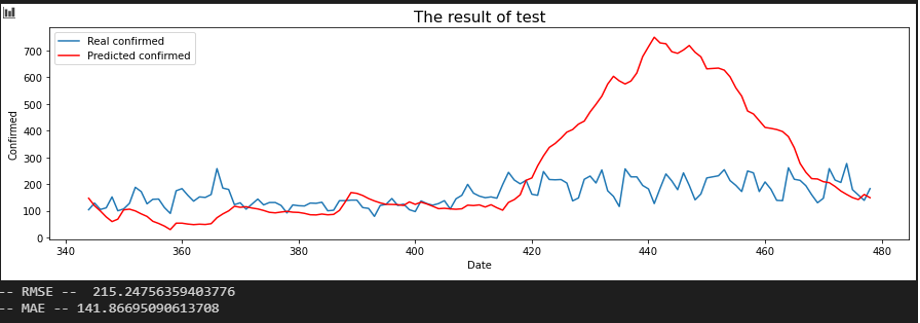
전체적으로 봤을 때, 주목할 만한 점을 확인해 보겠습니다. 서울과의 상관 관계 변화가 크게 있었던 지역 위주로 살펴보겠습니다.
먼저 시퀀스를 10일에서 20일로 늘렸을 때의 변화입니다. 대한민국의 중간에 위치하는 충남, 세종, 대전 등이 서울과의 상관 관계가 크게 증가하였고, 전남도 큰 폭으로 증가한 것을 확인할 수 있습니다.
이 지역들은 경인 지역에 비해서 조금 시간이 지나야 서울에 영향을 준다고 판단할 수 있겠습니다.
그 다음 시퀀스를 20일에서 30일로 늘렸을 때의 변화입니다.
인천, 강원, 충남, 경기가 소폭 상승한 것을 확인할 수 있습니다.
시퀀스를 20일에서 30일로 늘렸을 때 대전과 세종은 서울과의 상관 관계가 대폭 하락한 것을 확인할 수 있습니다.
이를 보면 대전과 세종은 20일 정도까지 서울에 영향력을 어느정도 행사하다가, 30일 정도가 지나면 서울에 대한 영향력이 크게 감소한다는 것을 알 수 있습니다.
Pearson correlation VS LSTM correlation
이제 최종적으로 피어슨 상관 관계 순위와 LSTM 상관 관계 순위를 비교해 보겠습니다.
- 검역은 해외 입국자를 의미



전체적으로 봤을 때, 피어슨 상관 관계 순위, LSTM 상관 관계 순위 둘 다 공통적으로 띄는 특징은, 서울과 가까운 지역이 높은 순위를 차지하고 있고 멀어질수록 낮은 순위를 차지하는 것을 알 수 있습니다. 당연한 결과겠죠?
다만 주목할 점은, 남한의 중앙에 위치해 있는 대전, 충북, 충남, 세종 지역은 확진자가 발생하고 20일 정도 즈음에 서울에 크게 영향력을 행사함을 확인할 수 있었습니다.
또 주목할 점은, 피어슨 상관 관계에서는 서울과 해외 입국 확진자에 대한 상관 관계가 엄청 낮았는데 반해, LSTM 상관 관계에서는 꽤 높은 순위에 위치하고 있는 것을 보실 수 있습니다. 이에 대해서 조금 더 알아보기 위하여 피어슨 상관관계 분석법에 조금 기술적인 부분을 추가하여 지역간의 상관관계를 다른 방향에서 확인했습니다.
그것은, 지역 간 시차를 두어 이를 가지고 상관관계를 분석하는 것입니다.
앞서 진행했던 피어슨 상관관계 분석법에 원하는 지역과 다른 지역간의 상관 관계 순위를 알아보면서 동시에 원하는 지역의 날짜를 비교할 지역의 날짜보다 앞당긴 데이터를 가지고 비교할 지역의 데이터와 상관 관계 비교를 해보는 것입니다.
이를 가지고 플롯을 그려봤습니다.
타겟 지역의 시간을 점차적으로 앞 당긴 것이기 때문에, 각 막대 그래프가 우상향 막대라면, 타겟 지역의 과거 데이터가 다른 지역의 데이터에 영향을 미친다는 의미입니다.
이를 입증해 보이기 위해 예시를 들어보겠습니다.
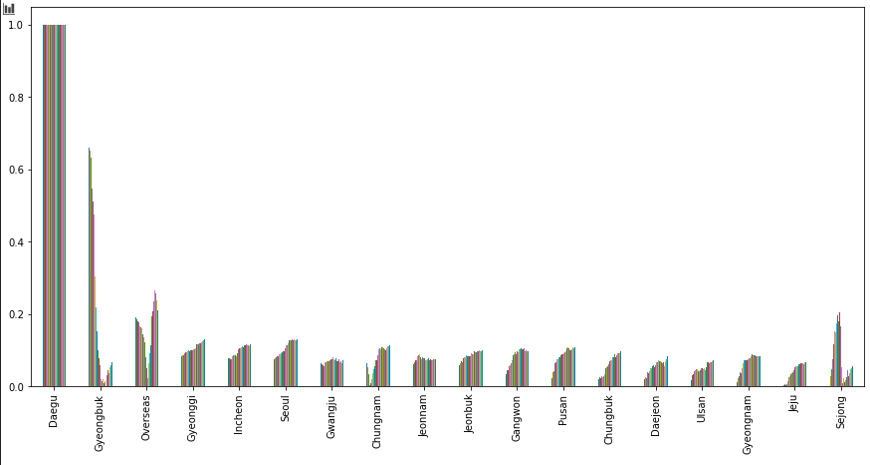
위 그림은 앞서 이상치(outlier)의 문제 때문에 상관 관계가 너무 낮아 제거했던 대구의 시간을 앞 당긴 데이터와 다른 지역간의 상관 관계를 나타낸 그림입니다.
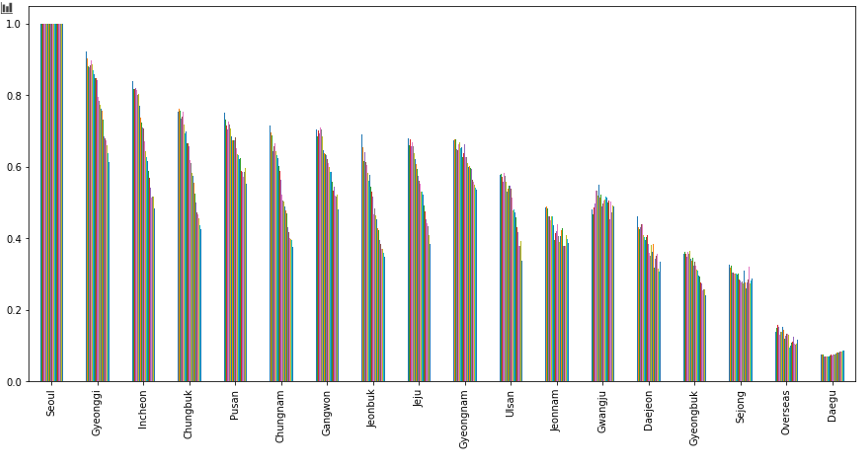
위 그림은 서울을 타겟으로 하고 이를 앞 당긴 데이터와 다른 지역간의 상관 관계를 나타낸 그림입니다.
대구는 코로나 초장기, 다른 지역에 막대한 영향을 주었습니다. 따라서 지역 전체적으로 보시면, 막대가 우 상향 모습을 하고 있는 것을 볼 수 있습니다. 반면 서울은 다른 지역에 영향을 크게 주지는 못하는 것 같습니다.
이제 해외 입국자 수를 타겟 데이터로 삼고 나머지 지역간의 상관관계를 보겠습니다.
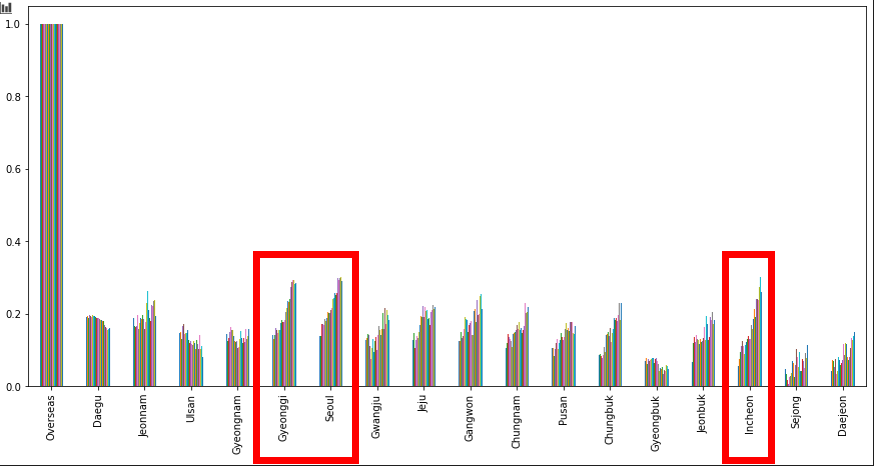
보면, 확연하게 거의 모든 지역이 우상향 막대를 하고 있는 것을 볼 수 있습니다. 그 중, 특히 인천국제공항, 서해 바다와 지리적으로 가까이 위치하고 있는 경기, 인천, 서울 지역이 다른 지역에 비해서 더욱 가파른 우상향 모양을 하는 것으로 보아, 이 지역들이 해외 입국 확진자에 큰 영향을 받는다고 판단이 되어집니다.
Conclusion
이를 보면, LSTM 상관 관계 분석법은 피어슨 상관 관계 분석법이 캐치하지 못하는 다른 부분들을 캐치해 냈다고 판단할 수 있습니다.
선형적인 관계밖에 보지 못하는 피어슨 상관 계수에 비해, 비선형성을 띄는 LSTM 상관 관계 기법은 상당히 다양한 요소들을 내포함을 알 수 있어, 크게 의미있는 시도라고 보여집니다.
'프로젝트' 카테고리의 다른 글
| [Project] 클러스터링을 이용한 성적 분배 (0) | 2023.01.23 |
|---|---|
| [Project] 고등학교 학생 성적에 미치는 요인 분석 (0) | 2023.01.23 |
| [Project] 18-19 시즌 EPL 승부예측 (0) | 2023.01.23 |
Contents
소중한 공감 감사합니다