프로젝트
[Project] 18-19 시즌 EPL 승부예측
- -
머신러닝 기법을 이용하여 영국 프리미어리그의 데이터를 학습하고, 이를 토대로 승부를 예측하도록 해보았습니다.
GitHub - kangmincho1/Side-Projects: Collection of side projects
Collection of side projects. Contribute to kangmincho1/Side-Projects development by creating an account on GitHub.
github.com
Dataset
Premier League 2018/2019 시즌 데이터
Download Soccer / Football Stats Database to CSV | FootyStats
Download Soccer / Football Stats Database to CSV and Excel Download our Soccer/Football Stats straight into CSV and Excel sheets to do your own analysis!
footystats.org
데이터의 구성은 row가 각 경기를 의미하며 column은 그 경기에 대한 갖가지 정보들로 구성되어있습니다.
Data preprocessing
feature column은 총 64개입니다.
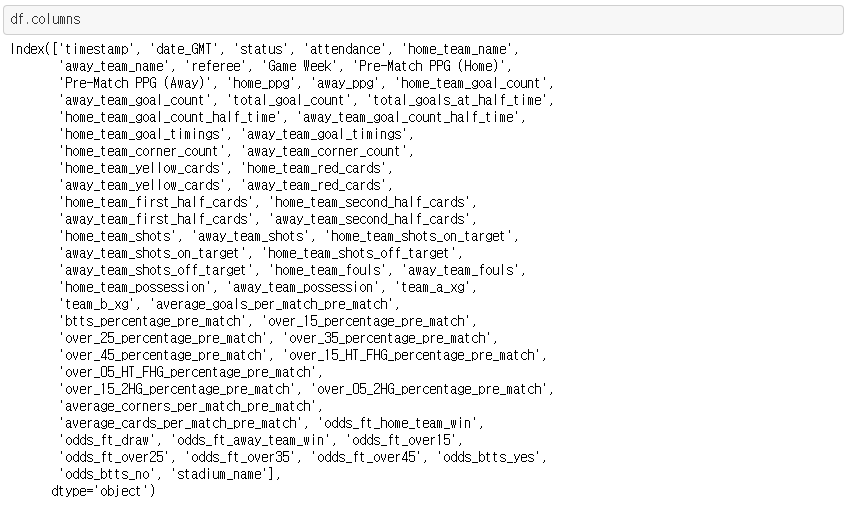
더 정확하고 의미있는 예측을 하기 위해서는 feature column을 조금 수정해야 합니다.
몇몇 feature column은 삭제해 주었습니다.
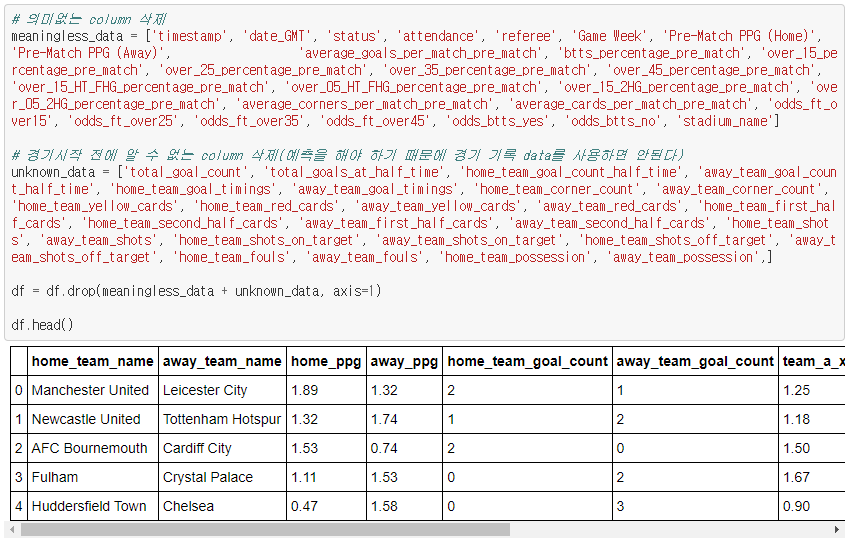
각 경기 정보의 label data를 생성하기 위해서 승/무/패 정보가 담겨있는 feature column을 생성해 주어야 합니다. label data는 홈 팀의 경기결과를 저장했습니다. 홈 팀의 경기결과를 안다면, 자연스럽게 어웨이 팀의 경기결과를 알 수 있기 때문입니다.
예를 들어, 인덱스 0번째 row를 보면, home_team_goal_count의 값은 2이고, away_team_goal_count는 1인 것을 볼 수 있습니다. 즉, 홈 팀인 맨체스터 유나이티드가 어웨이 팀인 레스터 시티를 2대 1로 이긴 것을 의미합니다. 이는 홈 팀 맨체스터 유나이티드의 승리입니다. 승/무/패에 대한 정보를 숫자로 저장해야 학습이 가능하므로 각각 2/1/0의 점수를 부여하였습니다.
아래는 이를 적용하는 코드입니다.
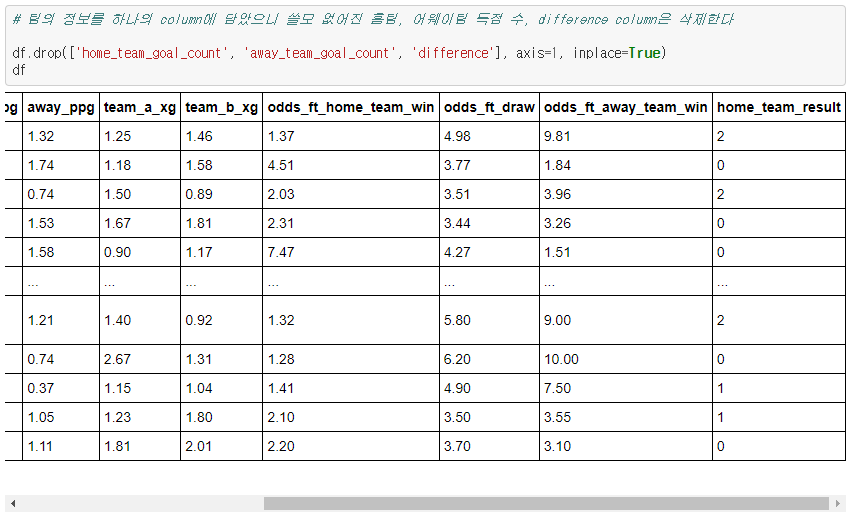
feature column 중 home_ppg, away_ppg 정보가 있습니다. ppg가 의미하는 것은 points per game으로, 해당 팀이 평균적으로 얻는 승점을 의미합니다. 이 데이터가 중요한 이유는, 이를 보면 상대적으로 잘하는 팀과 못하는 팀이 드러나기 때문입니다. 참고로 설명하자면, 축구는 한 경기당 승리하면 승점 3점, 비기면 1점, 패배하면 0점을 얻게 됩니다.
team_a_xg와 team_b_xg에서 xg가 의미하는 것은 expected goals입니다. 즉, 해당 팀의 예상되는 득점 수를 의미합니다. a와 b는 각각 홈, 어웨티 팀을 의미합니다. odds_ft_home_team_win, odds_ft_draw, odds_ft_away_team_win은 각각 홈 팀 승, 무승부, 어웨이 팀 승에 대한 배당률입니다.
저는 여기에 조금 더 유익한 정보를 추가하면 좋겠어서 데이터를 추가로 제작하였습니다.
유익한 데이터 추가
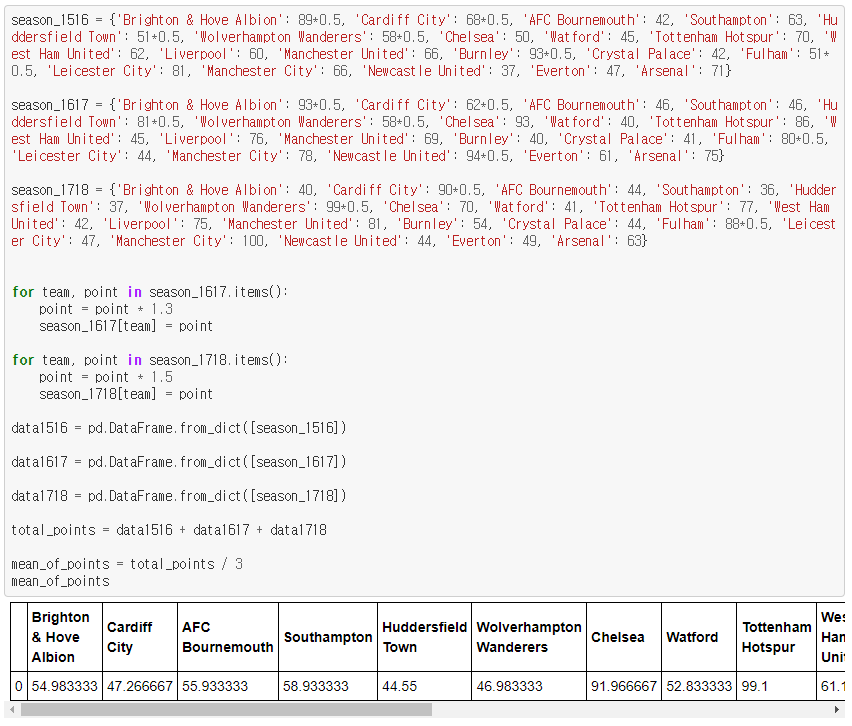
제가 추가한 데이터는 Premier League 2018/2019 시즌 기준 근 3년간(2015/2016, 2016/2017, 2017/2018)의 시즌의 최종 승점에 대한 정보입니다.
이는, Premier League에서 각 팀의 입지에 대한 정보를 매우 크게 함축하고 있다고 생각하여 넣었습니다.
EFL Championship에 대해서 잠깐 짚고 넘어가자면, 잉글랜드 축구는 20부리그까지 있습니다. 그 중 1부~4부 리그를 프로 단계라고 하며 이 사이에 강등과 승격을 통하여 리그간 팀의 이동이 매 시즌마다 존재합니다. 여기서 2부리그는 EFL Championship이라고 합니다. Premier League 하위 3개팀은 EFL Championship으로 강등되며, EFL Championship의 상위 두개 팀과 플레이오프를 거쳐 올라온 한 개 팀, 총 3개팀이 Premier League로 승격합니다.
따라서, Premier League의 팀 별 근 3년의 시즌 승점을 따지려면, 불가피하게 승격, 강등팀의 승점도 조사해야 합니다. 따라서 2015/2016, 2016/2017, 2017/2018 시즌의 EFL Championship 승점 정보도 알아야 합니다.
근 3년간 시즌의 승점을 처리하는 방법은 다음과 같습니다.
현재 시즌(2018/2019)과 가까운 시즌일수록 최종 승점에 더 높은 가중치를 부여합니다.
이는 당연한 것이, 최근의 폼이 현재의 폼과 제일 유사하기 때문입니다.
Premier League의 승점과 EFL Champoinship의 승점을 동일시하는 것은 맞지 않기 때문에, EFL Championship 승점에 패널티를 부여합니다.
따라서 각각에 곱해지는 가중치는 아래와 같습니다.
3시즌전(2015/2016) 최종 승점 * 1.0
2시즌전(2016/2017) 최종 승점 * 1.3
1시즌전(2017/2018) 최종 승점 * 1.5
EFL Championship 최종 승점 * 0.5
이를 종합한 근 3년간의 시즌 승점 계산식입니다.
{3시즌전 최종 승점 * 1.0 + 2시즌전 최종 승점 * 1.3 + 1시즌전 최종 승점 * 1.5} / 3
위의 과정을 코드로 작성해 보았습니다.
이제, 이 정보를 기존의 dataframe의 feature 정보로 넣어줘야 합니다.
home_team_name, away_team_name을 활용합니다.
column 명을 home_team_point, away_team_point로 변경하고, 새로 추가해준 승점 정보를 pd.to_numeric으로 변환해주어 오류가 없도록 합니다.
sklearn.preprocessing의 MinMaxScaler를 이용하여 데이터를 스케일링 해줍니다.
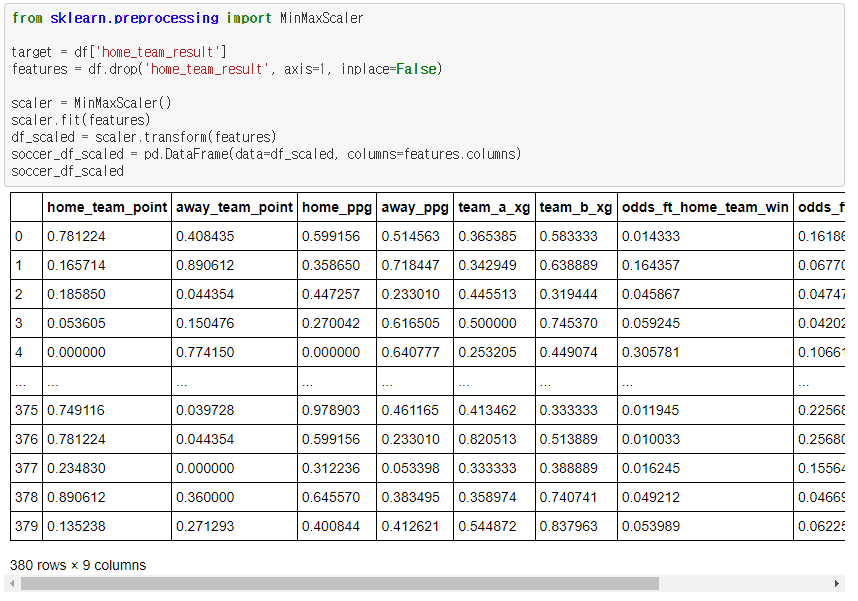
Classification
이제 머신러닝 기법을 이용하여 classification을 해볼 것입니다.
데이터의 label 값은 3종류이기 때문에 평가지표를 accuracy_score로 설정하였습니다.
sklearn에서 머신러닝 알고리즘을 import 해줍니다.
또한, 가장 좋은 알고리즘을 얻어내기 위하여 여러가지 머신러닝 알고리즘을 적용해봅니다.
매번 머신러닝 분류기로 학습시킬 때마다 다른 score가 나오기 때문에 이를 20번 score를 내게 한 뒤, 이 20번의 평균 score를 보도록 하게 했습니다.
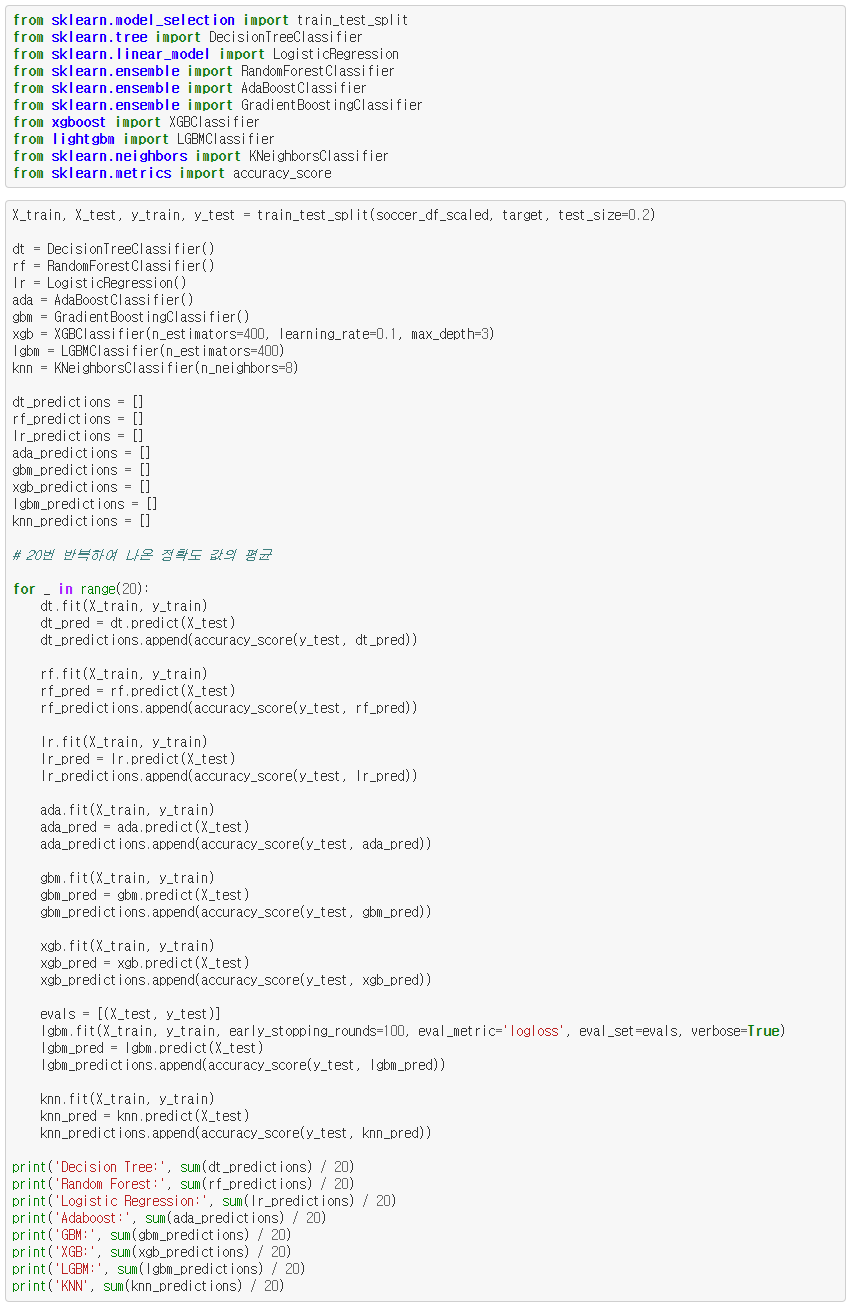
아래는 위 코드의 결과입니다. Logistic Regression이 약 64.47%의 정확도를 보이고 있고, Adaboosting Classifier가 약 63.16%의 정확도를 보이고 있습니다.
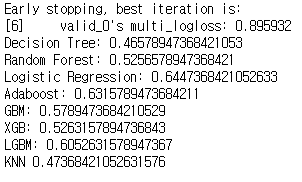
Voting Classifier로 정확도를 더 높여보았습니다.
정확도가 높았던 두개의 분류기를 Voting Classifier의 estimator로 사용해 보았습니다.
그 결과, Logistic Regression의 결과와 같은 것을 알 수 있었습니다.
즉, Voting Classifier로 분류했던 것은 별로 의미 없는 시도였습니다.
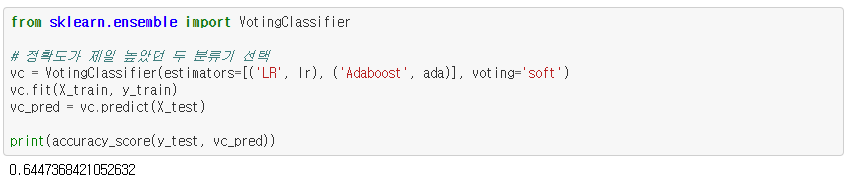
제일 성능이 좋았던 Logistic Regression을 하이퍼 파라미터 수정을 통해 성능을 조금 더 높여보았습니다.
그리드 서치 기법을 이용하여 최적의 성능을 보이는 파라미터를 구했고, 이는 {‘C’: 10, ‘penalty’: ‘l1’} 입니다.
그리드 서치의 best_estimator_ 함수를 이용하여 그 최적의 성능을 보이는 파라미터로 설정하여, 그 중에서도 최고의 esitmator를 구했습니다. 그 결과, 약 67.1%로 하이퍼 파라미터를 수정하기 전 보다 정확도가 더 올라간 것을 확인할 수 있습니다.
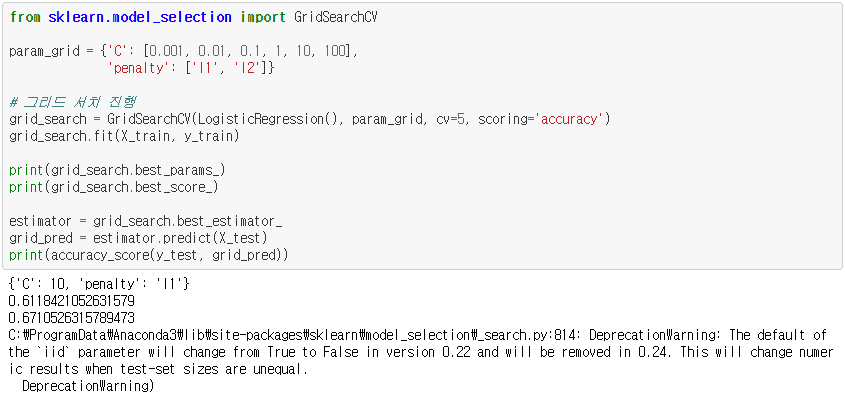
Result
아직 정확도가 60%라는 것이 조금 아쉬움이 남아 욕심을 부려보았습니다.^^
이번에는 Stacking ensemble을 이용하여 정확도를 높이는 시도를 해보았습니다.
Stacking ensemble은 두 개의 학습모델이 필요합니다.
하나는 개별적인 학습 모델이고, 또 다른 하나는 개별적인 학습 모델에서 학습되어진 결과들로 학습하는 모델입니다.
이 개별적인 학습 모델에는 여러가지의 분류기가 들어가게 됩니다.
위에서 정확도가 높았던 두 분류기인 Logistic Regression과 Adaboosting classifier 중 Adaboosint classifier를 최종 분류기로 선정하였습니다.
그 이유는, Logisitc Regression은 본래 데이터에 대한 학습 정확도가 다른 분류기들에 비해서 월등하게 좋기 때문에 최종 분류기로 설정하는 것보다는, stacking ensemble의 1차 모델에서의 분류기로 설정하여 본래 데이터에 대한 정확도를 더 높이는 것이 좋다고 판단되었습니다.
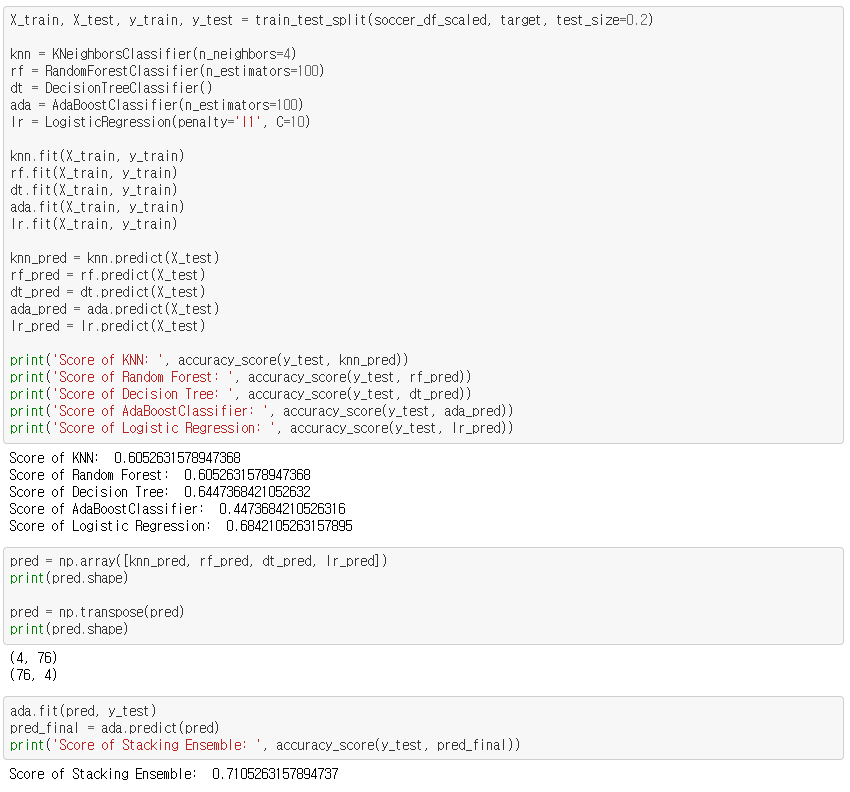
그 결과, 약 71.05%의 정확도를 보이는 모델을 탄생시켰습니다!
분류를 진행하면서 유독 이 데이터는 Logistic Regression의 정확도가 높았습니다.
왜 그랬을까 생각을 해봤는데, 이 Premier League 2018/2019 데이터는 다른 데이터 셋에 비해서 상대적으로 변수 간의 크기 스케일 차이가 별로 크지 않고 어느 일정 수준에서 약간씩만 다른 형태의 데이터입니다. 또한, 자료들의 분포도 고르게 분포돼 있으며, 이상치(outlier)가 거의 없다고 봐도 무방한 데이터였습니다.
로지스틱 회귀는 이렇게 설명변수 간 스케일 차가 작은 것에 좋은 성능을 보이며 균형 자료에 적합하다고 알고 있습니다. 따라서 이 Premier League 2018/2019 데이터가 로지스틱 회귀로 분류가 잘 되자 않았나 싶습니다.
추가적으로, 이 로지스틱 회귀에 하이퍼 파라미터 수정을 하였고, 스태킹 앙상블을 통해서 다른 분류기의 도움을 받아 더욱 더 높은 정확도를 얻게 되었습니다.
'프로젝트' 카테고리의 다른 글
| [Project] Interregional Correlation Analysis of COVID-19 Confirmed Cases using LSTM: linear and non-linear correlation analysis (1) | 2023.01.23 |
|---|---|
| [Project] 클러스터링을 이용한 성적 분배 (0) | 2023.01.23 |
| [Project] 고등학교 학생 성적에 미치는 요인 분석 (0) | 2023.01.23 |
Contents
소중한 공감 감사합니다