프로젝트
[Project] 클러스터링을 이용한 성적 분배
- -
대학에서는 상대평가 시, 일정 비율로 성적을 산출합니다. 그러나, 이렇게 성적을 산출하게 되면 A0와 B+ 구간에 있는 학생들이 다소 아쉬운 상황이 발생할 수 있다는 것입니다. 예를 들어, 어떤 학생은 91점을 받아 A0인데, 어떤 학생은 90.5점을 받아 B+를 받는 상황이 생기는 것입니다. 이는 수많은 학생들이 겪어 봤을 것이고, 저도 여러 번 겪어 봤습니다.
또한, 이 부분은 어쩔 때는 교수님들에게도 고역인 경우가 있습니다. 이런 경계구간에서 학생들의 성적이 모두 같아버린다면, 그 학생들 간의 출석, 태도, 과제 점수 등에 대해서 세부적으로 따져봐야 하기 때문입니다.
이렇게 억울하거나 귀찮아지는 일을 없애보고자 이 프로젝트를 진행했습니다.
GitHub - kangmincho1/Side-Projects: Collection of side projects
Collection of side projects. Contribute to kangmincho1/Side-Projects development by creating an account on GitHub.
github.com
Dataset
그럴듯한 데이터를 직접 생성했습니다. 제가 생성한 데이터는 가상의 학생들의 중간, 기말시험 점수와 출석 점수, 태도 점수, 과제 점수이며 이에 대해서 반영비율을 적용하여 최종 성적을 산출하여 이 성적에 대한 feature column을 생성한 데이터입니다.
중간고사, 기말고사는 100점이 만점이며, 출석, 태도, 과제 점수는 10점이 만점입니다. 반영비율은 중간고사 30%, 기말고사 30%, 출석 10%, 태도 10%, 과제 20%입니다.
따라서 만점은 100 * 0.3 + 100 * 0.3 + 10 * 0.1 + 10 * 0.1 + 10 * 0.2 = 66점입니다.
제가 만든 데이터를 확인해보겠습니다.

Data preprocessing
두가지 방법으로 데이터를 전처리 했습니다. 시각적으로 보기 쉽게 하기 위하여 차원축소를 진행했고, 그 중 PCA와 LDA 방법을 이용했습니다.
PCA
후에 설명할 것이지만, mean_shift 방법을 이용하여 군집화(clustering)를 했습니다.
PCA로 차원축소를 하게 되면, 따로 label data가 필요하지 않아 feature에 df를 대입했습니다.
(PCA는 비지도 학습이라 label data가 필요없지만, LDA는 지도 학습이라 target data가 필요)
StandardScaler, PCA, LDA, MeanShift까지 import 했습니다.

차원 축소를 하기 위해서는 정규화를 해줘야 합니다. 또한, 차원을 두개로 축소하여 시각적으로 이해 되기 쉽게 했습니다.

LDA
이제 LDA 데이터 전처리 과정입니다.
LDA는 지도학습이기에, label data가 필요합니다. grade column을 생성해 주도록 했습니다.
점수 산출 과정은 다음과 같습니다.
각각의 feature에 반영비율을 곱하여 더한 만점은 66점입니다.
(100 * 0.3 + 100 * 0.3 + 10 * 0.1 + 10 * 0.1 + 10 * 0.2 = 66)
이를 100점 만점으로 하기 위하여 각각의 점수에 100/66을 곱해주었습니다. 이를 최종 grade로 산출하였습니다.
아래는 그 코드입니다.

이번에는 label data가 있기 때문에, feature와 target 값에 저장을 따로 해줍니다.
df의 형태를 바꿔줍니다. 또한, PCA와 마찬가지로 차원 축소 과정이므로 데이터 정규화를 거칩니다.

Clustering
먼저 PCA를 사용하여 Mean_Shift 한 것입니다.
Mean_Shift 군집화를 선택한 이유는 추후에 설명하겠습니다.
MeanShift의 bandwidth를 18로 설정하여 군집을 5개 생성하였습니다. 그 이유는 A, B, C, D, E 5개의 성적을 군집화 할 것이기 때문입니다.


기존 dataframe에 군집화된 라벨들과 차원 축소되어 새로 생겨난 축을 추가해줍니다.
PCA로 차원 축소하여 Mean_Shift로 군집화 한 결과입니다.
성적 A/B/C/D/E 순으로 cluster를 나열해보면, 0/1/3/2/4가 되겠습니다.

다음은 LDA를 이용하여 Mean_Shift 한 것입니다.
이번에도 역시 Mean_Shift의 bandwidth는 18로 하여, 5개의 군집을 생성했습니다.
군집과 LDA를 통해 새롭게 생겨난 두개의 축을 기존 dataframe에 추가합니다.

이번에도 역시 성적 A/B/C/D/E 순으로 cluster를 나열하면 0/1/3/2/4입니다.

Result
먼저, Mean_Shift 군집화를 사용한 이유는 Mean_Shift 군집화는 K-means 군집화와는 다르게, 사전 군집정보를 요구하지 않습니다. 따라서 성적의 군집을 만들 때, 비교적 성적 평가자의 입장에서 더욱 자유롭게 성적을 분배할 수 있지 않을까 라는 생각에서 Mean_Shift 군집화를 선택하게 되었습니다.
이제 PCA와 LDA를 사용했을 때, 군집화 성능에 어느정도 차이가 있었는지 확인하겠습니다.

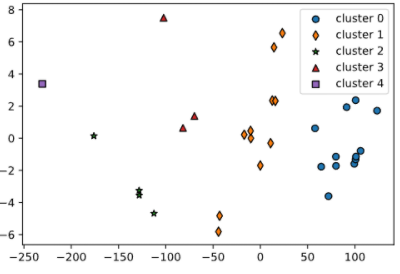
PCA 차원 축소를 이용해 군집화 한 것은 자세히 보면 cluster3과 cluster2의 경계가 모호합니다.
LDA 차원 축소를 이용해 군집화 한 것은 모든 cluster가 명확하게 구분돼 있는 것을 확인할 수 있습니다.
이를 이용해 성적 산출을 한다면 장단점이 있습니다.
먼저 PCA차원축소는 비지도 학습이기 때문에, 학생의 평가지표들을 종합하여 어떤 최종 결과물을 계산해 내지 않아도 됩니다. 따라서 성적 평가자의 입장에서는 편한 방법이 되겠습니다. 다만, 성적을 분배할 시 클러스터가 겹치는 현상이 발생하여 수월하게 성적 분배가 되지 않을 수 있습니다.
다음 LDA 차원축소는 지도 학습이기 때문에, 학생이 평가지표들을 종합하여 어떤 최종 결과물을 계산해 내야하고 이를 LDA 모델에 넣어줘야 합니다. 따라서 성적 평가자의 입장에서는 다소 귀찮은 방법이 될 수 있습니다. 다만, 성적을 분배할 시, PCA 차원축소보다 명확하게 군집화가 되었기 때문에 보다 편리하게 성적을 분배할 수 있을 것입니다.
'프로젝트' 카테고리의 다른 글
| [Project] Interregional Correlation Analysis of COVID-19 Confirmed Cases using LSTM: linear and non-linear correlation analysis (1) | 2023.01.23 |
|---|---|
| [Project] 고등학교 학생 성적에 미치는 요인 분석 (0) | 2023.01.23 |
| [Project] 18-19 시즌 EPL 승부예측 (0) | 2023.01.23 |
Contents
소중한 공감 감사합니다