논문 리뷰
[논문 리뷰] Are Transformers Effective for Time Series Forecasting?
- -
Are Transformers Effective for Time Series Forecasting?
Ailing Zeng1*, Muxi Chen1*, Lei Zhang2 , Qiang Xu1 1The Chinese University of Hong Kong 2 International Digital Economy Academy (IDEA)
논문링크: https://arxiv.org/pdf/2205.13504.pdf
장기 시퀀스 시계열 예측에서 과연 트랜스포머(Transformer)가 효과적인가?
NLP(Natural Language Processing)와 CV(Computer Vision) 분야 등 여러 task에서 트랜스포머 모델은 성능 향상에 있어서 효과적이었지만, 이를 시계열 데이터를 모델링 하는데에 있어서는 별로 효과적이지 않다는 것이 이 논문에서 중점적으로 제기하는 의문점이다.
Abstract
- 본 연구에서는 LTSF(Long-Time Series Forecasting)에 대한 Transformer 기반 솔루션의 유효성에 의문 제기
- Transformer에서 positional encoding을 사용하고 sub-series를 토큰으로 임베딩함으로써 일부 순서에 대한 정보를 보전하는 것은 도움이 되지만, self-attention 메커니즘의 본질적 특성으로 인해 시간 정보의 손실이 불가피
- LTSF-Linear라는 간단한 선형 모델을 사용해 Transformer 기반 시계열 예측 모델보다 뛰어난 성능을 보임
1. Introduction
Transformer는 다양한 응용 분야에서 뛰어난 성능을 보여주는 성공적인 시퀀스 모델링 아키텍처다.
최근에는 시계열 분석을 위한 Transformer 기반 솔루션이 급증했다.
Transformer의 주요한 작동 원리는 multi-head self attention mechanism이며 이는 장기 시퀀스 내의 요소들 간의 의미적 상관관계를 추출하는 뛰어난 능력을 갖고있다. 그러나 이는 순서를 고려하지 않는다. Positional encoding을 사용하여 일부 순서 정보를 보존하는 것은 도움이 되지만, 이후에 self attention을 적용하면 시간 정보의 손실은 불가피하다.
NLP와 같은 의미론적인 분야에서는 심각한 문제가 아니지만, 시계열 데이터는 순서 자체가 중요한 역할을 하기때문에 과연 transformer가 장기 시계열 예측에 효과적인지 의문을 제기한다.
자기 회귀적 다중 스텝 예측(Iterative Multi-Step Forecasting, IMS)은 오류 누적 문제가 있어 직접적 다중 스텝 예측(Direct Multi-Step Forecasting, DMS) 전략을 사용해 transformer 기반 LSTF 솔루션에 도전하여 성능을 검증한다.
LTSF-Linear는 과거 시계열을 일련의 선형 모델로 회귀하여 미래 시계열을 직접 예측한다.
놀랍게도, LTSF-Linear가 기존 복잡한 transformer 기반 모델들보다 모든 경우에 더 나은 성능을 보인다.
2. Preliminaries: TSF Problem Formulation
시계열 데이터의 변수가 C개라고 할때, 과거 데이터의 형태는 아래와 같다.
$X = {X_{t}^{(1)}, \ldots, X_{t}^{(C)}}{t=1}^{L}$
$L$은 lookback window의 크기이고, $X{t}^{(i)}$는 t번째 시간 단계에서 $i$번째 변수의 값이다.
시계열 예측은 $T$개의 미래 시간 단계에 대한 값 $X̂ = {X̂_{t}^{(1)}, \ldots, X̂_{t}^{(C)}}_{t=L+1}^{L+T}$를 예측하는 것이다. $T > 1$인 경우, 반복 다중 스텝(IMS) 예측은 단일 스텝 예측기를 학습하고 이를 반복적으로 적용하여 다중 스텝 예측을 얻는다. 반면, 직접적인 다중 스텝(DMS) 예측은 한번에 다중 스텝 예측 목표를 최적화한다.
DMS 예측 결과에 비해 IMS 예측은 자기 회귀 추정 절차 덕분에 분산이 작지만, 불가피하게 오차 누적 효과에 영향을 받는다.
따라서 IMS 예측은 높은 정확도의 단일 스텝 예측기가 있는 경우에 적합하며, T가 비교적 작을 때 선호된다.
반면, DMS 예측은 편향되지 않은 단일 스텝 예측 모델을 얻기 어려운 경우나 T가 큰 경우에 더 정확한 예측을 생성한다.
3. Transformer-Based LTSF Solutions

Transformer 기반의 LTSF 솔루션은 기존 Transformer 모델의 제약을 해결하고 성능과 효율성을 개선하기 위해 다양한 설계 요소를 도입한 연구들이 많이 진행되고 있다. 이러한 설계 요소들은 다음과 같다.
- Time series decomposition
- 데이터 전처리를 위해 평균이 0이 되도록 정규화하는 것이 일반적이다. Autoformer와 FEDformer는 각각의 뉴럴 블록 뒤에 계절-추세 분해를 적용하여 원본 데이터를 예측 가능한 형태로 만든다. 이를 위해 이동 평균 커널(moving averate kernel)을 사용하여 시계열의 추세-주기성 성분을 추출하고, 원본 시퀀스와 추세 성분 간의 차이를 계절성 성분으로 간주한다.
- Input embedding strategies
- Transformer 아키텍처의 self-attention 계층은 시계열의 위치 정보를 보존하지 못한다. 그러나 시계열의 로컬 위치 정보(시계열의 순서)와 전역적인 시간 정보(주, 월, 연도와 같은 계층적 타임스탬프 및 휴일, 이벤트와 같은 타임스탬프)는 중요하다. 이를 위해 SOTA Transformer 기반 방법들은 fixed positional encoding, channel projection embeddings, learnable temporal embeddings과 같은 여러 임베딩을 입력 시퀀스에 주입한다. 또한, 시간 합성곱 계층을 사용하는 temporal embeddings나 learnable timestamps도 도입된다.
- Self-attention schemes
- Transformer는 self-attention mechanism을 통해 쌍으로 구성된 요소들 간의 의미적 종속성을 추출한다. 기존의 Transformer의 $O(L^2)$ 시간 및 메모리 복잡도를 줄이기 위해 최근 연구에서는 효율성을 위해 두 가지 전략을 제안하고 있다. LogTrans와 Pyraformer라는 방법을 제시한다.
- Decoders
- 기본 Transformer 디코더는 자기-회귀적인(autoregressive) 방식으로 시퀀스를 출력하며, 특히 장기 예측에서는 느린 추론 속도와 오류 누적 효과가 발생한다. Informer는 DMS(Direct Multi-Step) 예측을 위해 생성형 스타일의 디코더를 설계한다. 다른 Transformer 변형 모델들도 유사한 DMS 전략을 사용한다. 예를 들어, Pyraformer는 공간-시간 축을 연결하는 완전 연결층을 디코더로 사용한다. Autoformer는 추세-주기성 성분과 시즌성 성분의 개선된 분해된 특징 두 가지를 합쳐 최종 예측을 얻는다. FEDformer는 주파수 어텐션 블록을 활용한 분해 기법을 사용하여 최종 결과를 디코딩한다.
4. An Embarrassingly Simple Baseline

이전에 제안된 Transformer 기반 LTSF 솔루션들과 비교되는 baseline인 "LTSF-Linear"을 소개한다. 이는 가장 단순한 DMS 모델로, 선형 계층을 통해 과거 시계열 데이터를 미래 예측에 직접 회귀하는 방식으로 구성된다. LTSF-Linear은 각 변수에 대해 가중치 합 연산을 수행하며, 서로 다른 변수 간에 가중치를 공유하고 공간적 상관 관계를 모델링하지 않는다.
LTSF-Linear은 기본적인 선형 모델로, 다양한 도메인(금융, 교통, 에너지 등)의 시계열을 처리하기 위해 전처리 방법을 결합한 두 가지 변형인 "DLinear"과 "NLinear"를 제시한다.
- DLinear
- Autoformer와 FEDformer에서 사용된 분해 기법과 선형 계층을 조합한 모델로, 원시 데이터 입력을 이동 평균 커널(moving average kernel)을 통해 추세 성분과 나머지(계절성) 성분으로 분해한다. 그 후, 각 성분에 대해 두 개의 일련의 선형 계층을 적용하고, 두 특징을 합산하여 최종 예측을 얻는다. 추세를 명확히 처리함으로써 DLinear는 데이터에 명백한 추세가 있는 경우에 기본 선형 모델의 성능을 향상시킨다.
- NLinear
- 데이터셋에서 분포 변화가 있는 경우 LTSF-Linear의 성능을 향상시키기 위해 사용된다. NLinear은 입력을 시퀀스의 마지막 값으로부터 뺀 다음, 선형 계층을 통과시킨 후 빼진 부분을 최종 예측 전에 다시 더한다. NLinear의 뺄셈과 덧셈은 입력 시퀀스의 간단한 정규화 방법이다.
5. Experiments
5.1. Experimental Settings
- Dataset: ETT(전기 변압기 온도), 교통, 전기, 날씨, ILI, 환율 등 9개의 실제 다변량 시계열 데이터셋
- Evaluation metric: MSE(Mean Sqaured Error), MAE(Mean Absolute Error)
- Compared methods: FEDformer, Autoformer, Informer, Pyraformer, LogTrans 등의 최근 Transformer 기반 방법들과 마지막 값을 반복하는 단순한 baseline인 Closest Repeat (Repeat)
5.2. Comparison with Transformers
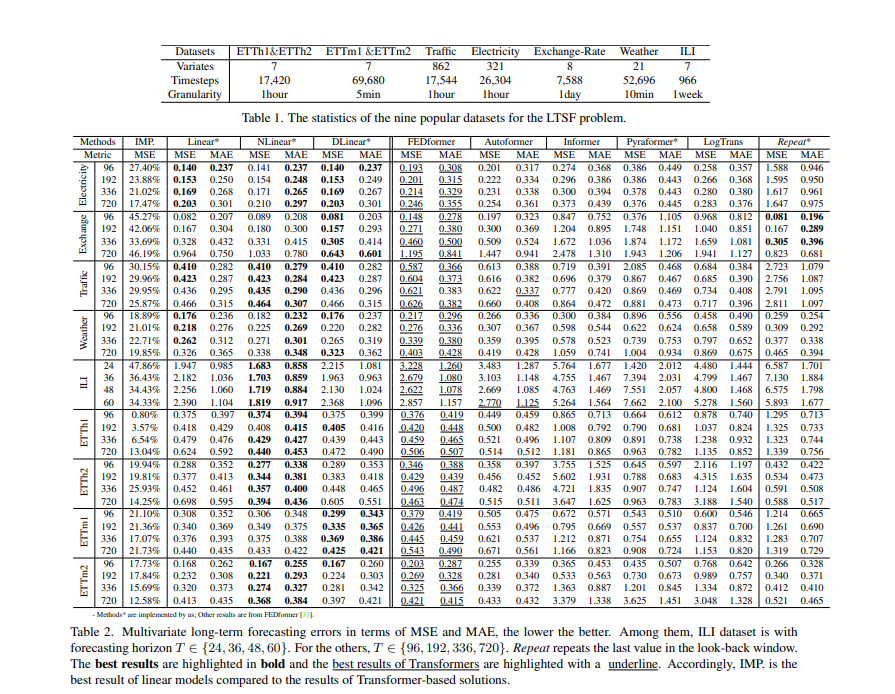
Quantitative results
- table 2에서 언급된 모든 Transformer 기반 방법들을 9개의 벤치마크 데이터셋에서 평가함.
- 놀랍게도, 대부분의 경우 LTSF-Linear의 성능이 SOTA인 FEDformer를 20% ~ 50% 개선함.
- LTSF-Linear은 변수 간의 상관관계를 모델링하지 않음에도 불구하고 우수한 성능을 보임.
- NLinear과 DLinear은 데이터 분포 변화와 추세-계절성 특징을 처리하는 데 우수성을 보임.
- ETT 데이터셋의 단변량 예측 결과도 제공되었는데, LTSF-Linear은 여전히 Transformer 기반 LTSF 솔루션들보다 큰 차이로 우수한 성능을 보임.
- FEDformer는 ETTh1에서 경쟁력 있는 예측 정확도를 보임(FEDformer가 주파수 처리와 같은 고전적인 시계열 분석 기법을 사용하여 시계열 귀납적 편향을 가져오고 시간적 특성 추출 능력에 도움이 되기 때문)

Qualitative results
- 전기, 환율, ETTh2와 같은 세 가지 시계열 데이터셋에 대한 Transformer 기반 방법과 LTSF-Linear의 예측 결과를 그래프로 표현함.
- 입력 시퀀스 길이가 96 steps이고 출력 범위가 336 steps인 경우, Transformer 방법들은 전기와 ETTh2의 미래 데이터의 크기와 편향을 캡처하지 못함.
- 또한, 환율과 같은 비주기적인 데이터에서 적절한 추세를 예측하기 어려움.
- 이러한 현상은 기존 Transformer 기반 솔루션들이 LTSF 작업에 적합하지 않음을 더욱 보여줌.
5.3. More Analyses on LTSF-Transformers
- 기존의 LTSF-Transformers는 긴 입력 시퀀스에서 시간적 관계를 잘 추출할 수 있는가?
- 입력 look-back 윈도우의 크기는 예측 정확도에 큰 영향을 미침. 큰 look-back 윈도우 크기로 모델을 구성할수록 성능이 향상될 것으로 기대됨.
- 실험에서 기존의 Transformer 기반 모델들은 look-back 윈도우 크기가 증가함에 따라 성능이 저하되거나 일정함.
- 반면, LTSF-Linear 모델들은 look-back 윈도우 크기가 증가함에 따라 성능이 크게 향상됨.
- 기존의 솔루션들은 긴 시퀀스를 주면 시간적인 노이즈에 과적합(overfitting)되기 쉽고, 입력 크기 96이 대부분의 Transformer에 적합한 크기임을 보여줌.
- Long-term forecsting을 하기 위해 얻을 수 있었던 정보는 무엇인가?
- 장기 예측에서는 look-back 윈도우의 시간적인 동태가 단기 예측 정확도에 큰 영향을 미침.
- 장기 예측은 주로 추세와 주기성을 잘 포착할 수 있는 모델에 의존함. 즉, 예측 범위가 더 멀어질수록 look-back 윈도우 자체의 영향은 줄어듦.
- 실험 결과, SOTA Transformer 모델들의 성능이 약간 하락하는데, 이는 이러한 모델들이 인접한 시계열 시퀀스에서 유사한 시간적 정보만을 포착하기 때문임.
- 데이터셋의 본질적 특성을 포착하는 데는 일반적으로 많은 수의 매개변수가 필요하지 않으며, 하나의 매개변수로 주기성을 표현할 수 있음.
- 너무 많은 매개변수를 사용하면 과적합이 발생할 수 있으며, 이는 LTSF-Linear이 Transformer 기반 방법보다 성능이 우수한 이유 중 일부를 설명함.
- Self-attention이 LTSF에 효과적인가?
- 기존의 Transformer 구조에서 self-attention과 같은 복잡한 구성 요소가 필수적인지 검증함.
- table 4에서 Informer를 점진적으로 선형화함.
- self-attention 레이어를 선형 레이어로 대체한 Att.-Linear를 사용하여 성능이 놀랍게도 향상됨.
- FFN과 같은 보조 디자인을 제외한 Embed + Linear 모델도 성능이 향상됨.
- 이러한 결과는 기존의 LTSF 벤치마크에서 self-attention과 다른 복잡한 모듈이 필요하지 않음을 나타냄.

- 기존의 LTSF-Transformers는 시간적인 순서를 잘 보존하는가?
- self-attention은 순서에 무관하게 동작하는데, 시계열 예측에서는 순서가 중요한 역할을 함.
- 기존의 Transformer 기반 방법들도 위치 및 시간적인 임베딩을 사용하더라도 시간 정보 손실에 대한 문제가 여전히 존재함.
- table 5에서 원래 설정과 입력 순서를 섞은 경우를 비교함.
- 모든 Transformer 기반 방법들은 입력 시퀀스가 무작위로 섞여도 성능이 크게 흔들리지 않음.
- 그에 반해, LTSF-Linear의 성능은 크게 저하됨.
- 이는 기존의 Transformer 기반 방법들이 위치 및 시간적인 임베딩에도 시간적인 관계를 제대로 보존하지 못하고, 노이즈가 많은 금융 데이터에 과적합하기 쉽다는 것을 나타냄.

- 다른 임베딩 전략의 효과는 어떤가?
- Transformer 기반 방법에서 사용되는 위치 및 타임스탬프 임베딩의 이점을 조사함.
- table 6에서 Informer의 위치 임베딩(positinal embedding) 없이 예측 오류를 비교함.
- 위치 임베딩 없이는 Informer의 예측 오류가 크게 증가함.
- 타임스탬프 임베딩 없이는 예측 길이가 증가함에 따라 Informer의 성능이 점차 저하됨.
- Informer는 각 토큰에 대해 단일 시간 단계를 사용하기 때문에, 토큰에 시간 정보를 포함시키는 것이 필요함.
- FEDformer와 Autoformer는 시간적 정보를 임베딩하기 위해 타임스탬프 시퀀스를 입력으로 사용하므로, 고정된 위치 임베딩 없이도 유사하거나 더 나은 성능을 얻을 수 있음.
- 그러나 타임스탬프 임베딩 없이는 Autoformer의 성능이 급격히 하락함. 이는 전역적인 시간 정보의 손실 때문임.
- FEDformer의 경우, 시간적인 노이즈가 적은 데이터셋인 경우에도 temporal inductive bias를 도입하여 상대적으로 영향이 적음을 보여줌.

- 기존의 LTSF-Transformers에서 훈련 데이터 크기는 제한적인 요소인가?
- Transformer 기반 솔루션의 성능이 벤치마크 데이터셋의 크기가 작아서 나오는 것인지에 대한 논란이 있음.
- TSF는 수집된 시계열 데이터에서 수행되며, 훈련 데이터 크기를 확장하기는 어려움.
- 실제로 훈련 데이터 크기가 모델 성능에 큰 영향을 미침을 실험으로 확인함.
- Traffic 데이터셋에서 전체 데이터셋(17,544*0.7 시간)으로 훈련된 모델(Ori.)과 줄인 데이터셋(8,760 시간, 1년)으로 훈련된 모델(Short)의 성능을 비교함.
- 의외로 줄인 훈련 데이터로 훈련한 모델의 예측 오류가 대부분의 경우 더 낮음을 확인함.
- 이는 전체 연간 데이터가 더 명확한 시간적 특징을 유지하기 때문일 수 있음.
- 훈련 데이터의 양을 줄여야 한다는 결론을 내릴 수는 없지만, 적어도 기존의 벤치마크에서는 훈련 데이터 규모가 모델 성능의 제한적인 이유는 아닌 것으로 나타남.
- 효율성이 진정한 최우선 순위인가?
- 기존의 LTSF-Transformers는 vanilla Transformer의 $O(L^2)$ 복잡도를 개선할 수 있다고 주장함.
- 그러나 실제 추론 시간과 메모리 비용이 개선되었는지, 메모리 문제가 현실적으로 심각한지에 대해서는 명확하지 않음.
- table 8에서 실제 효율성을 5회 실행한 결과를 비교함.
- 실제로 vanilla Transformer와 비교했을 때, 대부분의 Transformer 변형 모델들은 실제 추론 시간과 매개변수 측면에서 유사하거나 심지어 더 나쁜 결과를 나타냄.
- 이러한 후속 연구들은 실제 비용이 더 높아지도록 추가적인 디자인 요소를 도입함.
- 또한, vanilla Transformer의 메모리 비용은 실제로 받아들일 수 있는 수준으로 낮아지고 있음.
- 따라서 효율성은 단순히 모델 설계의 우선 순위가 아니라 다른 요소와 균형을 이루어야 하는 것으로 나타남.


6. Conclusion and Future Work
Conclusion
이 연구는 장기 시계열 예측 문제에 대한 기존의 Transformer 기반 솔루션의 효과적인 성능에 대해 의문을 제기한다.
본 연구는 간단한 선형 모델인 LTSF-Linear을 DMS 예측 기준선으로 사용하여 주장을 검증한다.
본 연구를 통해 선형 모델을 제안한 것이 아니라 중요한 질문을 제기하고 놀라운 비교를 보여주며, 다양한 관점을 통해 LTSF-Transformers가 주장된 것만큼 효과적이지 않다는 것을 입증하는 것이 주 목표이다.
본 연구가 향후 시계열 예측에 도움이 될 가능성은 무궁무진하다.
Future work
LTSF-Linear은 모델 용량이 제한적이며, 강력한 해석 가능성을 가진 간단한 baseline 역할만 수행한다. 예를 들어, 1-layer linear network는 변화점에 의한 시간적으로 다이나믹한 변화를 캡처하기 어렵다.
LTSF-Linear는 LTSF 문제에 대한 새로운 모델 디자인, 데이터 처리 및 벤치마크에 대한 큰 잠재력이 있다고 믿는다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Stock market network based on bi-dimensional histogram and autoencoder (0) | 2023.03.03 |
|---|
Contents
소중한 공감 감사합니다