논문 리뷰
[논문 리뷰] Stock market network based on bi-dimensional histogram and autoencoder
- -
Intelligent Data Analysis 26 (2022) 723–750 723 DOI 10.3233/IDA-215819 IOS Press
Stock market network based on bi-dimensional histogram and autoencoder
Sungyoon Choia , Dongkyu Gwaka , Jae Wook Songb and Woojin Changa,c,d,∗ aDepartment of Industrial Engineering, Seoul National University, Seoul, Korea bDepartment of Industrial Engineering, Hanyang University, Seoul, Korea c Institute for Industrial Systems Innovation, Seoul National University, Seoul, Korea dSNU Institute for Research in Finance and Economics, Seoul National University, Seoul, Korea
출처: https://content.iospress.com/articles/intelligent-data-analysis/ida215819
S&P 500의 상위 400개의 주식 데이터를 2D 히스토그램, 오토인코더, PMFG 알고리즘을 이용하여 stock market network를 만들고 이를 통해 얻어질 수 있는 주식 포트폴리오는 다른 벤치마크 주식 포트폴리오에 비해 좋은 투자 성능을 보인다는 주제
전반적인 정리
- S&P 500의 상위 400개 주식 데이터를 이용
- 2D 히스토그램에 오토인코더 적용
- 오토인코더를 통해 추출된 의미있는 특성(feature)들의 히스토그램의 거리행렬에 PMFG(Planar Maximally Filtered Graph) 알고리즘을 적용하여 stock market network 제작
- 만들어진 stock market network는 2D 히스토그램의 latent space를 의미
- Stock market network의 구조적 특성은 2D 히스토그램의 분산과 관련있음
- 2D 히스토그램 네트워크의 주변 노드 집합 포트폴리오가 성능이 제일 좋음(샤프 비율이 높음)
Abstract
S&P 500을 분석하기 위한 2D 히스토그램과 오토인코더를 사용한 딥러닝 프레임워크를 소개한다.
2D 히스토그램 네트워크에서의 주변부 노드가 다른 벤치마크 주식 포트폴리오보다 좋은 투자 성능을 보인다.
1. Introduction
이 논문은 주식 데이터로부터 얻어진 2D 히스토그램을 오토인코더로 축소하고, 이 축소되어 나온 특성(feature)들을 기반으로 PMFG 알고리즘을 이용하여 2D 히스토그램 네트워크를 구축한 것이 색다른 방법이다.
2D 히스토그램 네트워크는 주식 투자 포트폴리오에 적용됐다. 네트워크의 주변부 주식들로 구성된 포트폴리오가 중심부 주식들로 구성된 포트폴리오보다 성과가 좋다. 이 특성을 기반으로 포트폴리오 적용 측면에서 히스토그램 네트워크의 유용성을 조사한다.
2. Related work
2.1 Stock market network
PMFG(Planar Maximally Filtered Graph) 알고리즘에 관한 설명
2.2 Autoencoder in the stock market
오토인코더에 관한 설명
3. Data and methods
데이터는 2006년 2월 3일부터 2019년 9월 30일까지 S&P 500에 포함된 주식들(상위 400개 주식)의 일일 가격과 거래량(3459개의 데이터 포인트)으로 구성되어 있다.
3.1 Bi-dimensional histogram
관찰 가능한 모든 쌍의 갯수를 M이라고 하면, M은 위와 같이 정의된다.
과 는 각각 첫번째, 두번째 변수에 관한 grid bin의 개수를 의미.
도수(frequency) 는 위의 식을 만족한다.
- 오토인코더 모델 구조와 학습 과정에서의 시간 복잡도를 고려하여 주가와 거래량 데이터의 범위를 상한 99% 분위, 하한 1% 분위로 설정
- 이 구간을 11개의 bin으로 나누어 11개의 주가와 거래량 데이터가 11개의 카테고리로 나뉨(즉, , 는 11)
- 여기서의 M 즉, 도수의 총합은 250
는 각 종목별 2D 히스토그램의 특징을 보기위한 분포 값이며 이는 X, Y 축 각각의 주변분포(marginal distribution)의 표준편차의 내적으로 구해진다.
3.2 Auto-encoder
- 이 논문에서 오토인코더가 쓰인 주 목적은, 2D 히스토그램의 latent vector를 얻기 위함
- 400개의 2D 히스토그램은 데이터가 너무 적어 주가, 거래량 데이터에 gaussian noises를 추가하여 augmentation 함
- training set, validation set의 비율은 무작위로 80%, 20%으로 설정
- MSE가 평가지표일 때, 오토인코더가 PCA보다 좋은 성능을 나타냄
3.3 Stock market network analysis
각 주식들의 2D 히스토그램을 인코더를 통해 latent vector로 변환한다. 각 관찰 기간동안, i번째 주식의 latent vector는 32 차원의 벡터로 표현된다.
위의 latent vector는 2D 히스토그램의 압축된 피처 벡터이다.
구해진 각 주식들의 latent vector들 간의 유클리드 거리를 계산하여 distance matrix 를 정의한다. 이 는 유클리드 거리 로 구성된다.
기존에 널리 쓰이는 (주가 기반 distance matrix)는 로 구성된다.
*는 주가들간의 Pearson correlation임.
Distance matrix 와 는 fully connected 되어 있으며, PMFG(Planar Maximally Filtered Graph) 알고리즘을 이용해 distance matrix의 중요한 정보는 남기면서 noise는 필터링함. 주식들의 topology information을 기반으로 network analysis를 함.
histogram network, price network
로 부터 구성된 PMFG를 각각 histogram network, price network라고 함.
네트워크에서의 개별적인 주식특징은 네트워크 중심성(network centrality)에 의해서 정량화 될 수 있음.
3.4 Portfolio model development
주가 네트워크에서 주변 노드(peripheral nodes)를 활용하여 포트폴리오를 구성하는 것은 포트폴리오 성능에 있어서 큰 이점이 있음. 주변 노드가 네트워크의 다른 노드와 관련성이 적다는 점에서 중심 노드(central nodes)와 비교했을 때, 뚜렷한 특징을 가질 수 있음.
- 히스토그램 네트워크의 주변성(peripherality)에 따라 포트폴리오의 특성을 파악한다.
- 투자 활용 측면에서 히스토그램 네트워크(histogram networks)가 주가 네트워크(price networks)에 비해서 이점을 갖는지 조사한다.
4. Experimental results
히스토그램 네트워크(histogram networks)의 투자 유용성을 조사한다.
4.1 Properties of bi-dimensional histogram
히스토그램 분산(histogram dispersion)이라고 할 수 있는 를 이용하여 2D 히스토그램의 특성을 분석한다.
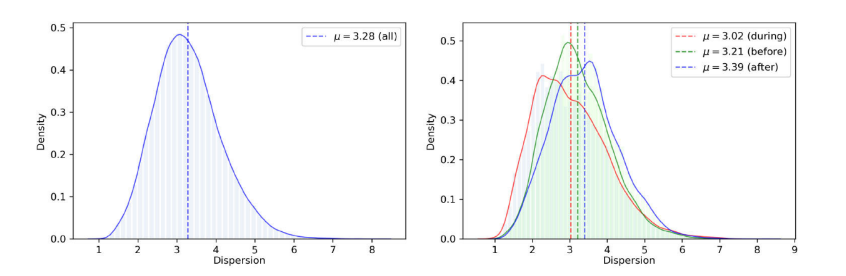
시장 상황에 따라서 의 분포가 달라짐. 2008년 금융위기(서브프라임 모기지 사태) 기간에는 금융위기 기간이 아닐 때보다 의 분포가 왼쪽으로 편향되며, 양의 왜도(right skewed)이다. 또한, 금융위기 기간에는 평균값(mean)과 중앙값(median)이 금융위기 기간이 아닐 때보다 작다. 반대로, 표준편차(standard deviation)는 금융위기일때 더욱 크게 나타난다.
대부분의 종목에서 2008년 금융위기 당시 값이 감소했다. 이는 2D 히스토그램의 분산이 감소했다는 것이며, 변동성이 작아졌다는 것을 의미한다.
각 종목간의 상관관계를 따져보면, 대부분의 종목은 양의 상관관계를 갖지만, FINC과 REES는 다른 산업 종목들과 음의 상관관계를 갖는다. 이는 FINC과 REES의 2D 히스토그램의 분산이 S&P 500 종목들의 2D 히스토그램의 분산이 증가할 때, 감소한다는 의미이다.
4.2 Dimensional reduction result of the bi-dimensional histogram
주식의 2D 히스토그램은 noise가 많아, 오토인코더를 사용하여 차원 축소하고 latent vector 추출.
4.3 Properties of bi-dimensional histogram network
각 주식의 2D 히스토그램의 latent vectors는 히스토그램 네트워크(histogram network)의 노드로 표현된다.
는 와 의 차의 절댓값을 의미한다. 여기서 는의 평균을 의미함.
와 shortest path length는 양의 상관관계(positive correlation)이며, 이는 더 큰 값을 가진 노드는 더 긴 shortest path를 가진다는 것을 의미한다.
다른 노드와 더 긴 shortest path를 가진 노드들은 가장자리(periphery)에 위치하는 경향이 있음.
즉, 가 큰(분산도가 큰) 노드들은 히스토그램 네트워크의 주변 노드인 경향이 있음.
결론적으로, 히스토그램 네트워크(histogram network)가 주식의 분포특성을 보여주기 적합하고, 오토인코더는 2D 히스토그램의 latent feature를 효과적으로 뽑는다는 것을 확인함.
4.4 Comparison of histogram network with price network
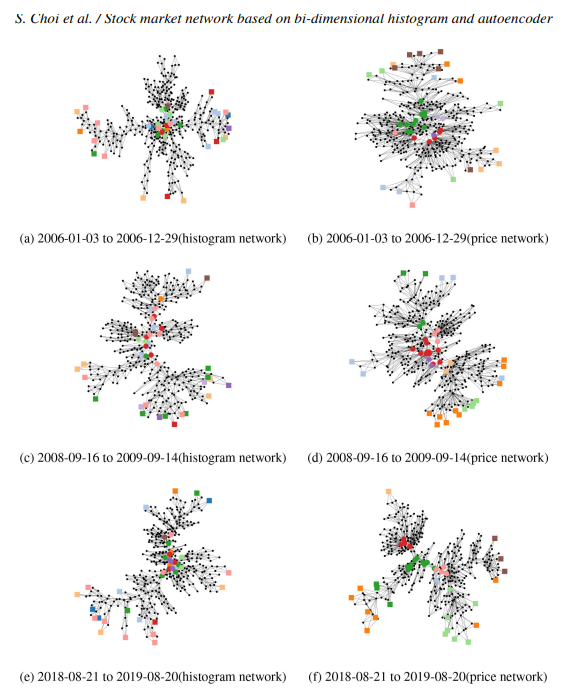
위 그림은 주변성(peripherality)에 따른 상위, 하위 20개의 노드를 히스토그램 네트워크(histogram network), 주가 네트워크(price network)로 나타낸 것.
히스토그램 네트워크(histogram network)의 노드 구성이 주가 네트워크(price network)의 노드 구성보다 다양하다.
2D 히스토그램의 특성은 주변 노드의 속성으로부터 결정될 수 있음을 보여줌.
주가 네트워크(price network)의 종목 다양성이 낮기 때문에 shortest path length가 히스토그램 네트워크(histogram network)보다 짧은 경향이 있음.
4.5 Application to stock portfolio
위의 내용을 참고하여, 네트워크의 주변 노드에 해당하는 종목들로 포트폴리오를 구성함.
히스토그램 네트워크(histogram network)에서 주변노드(peripheral nodes)로 구성된 포트폴리오는 중심노드(central nodes)로 구성된 포트폴리오보다 sharpe ratio가 높음. 주변노드로 구성된 포트폴리오는 다른 종목에 대한 의존도가 낮아 효과적임.
참고로, 몇몇 이전 연구들에서 주가 네트워크(price network)의 주변 노드로 구성한 포트폴리오가 중심 노드로 구성한 포트폴리오보다 좋은 전략임을 보여왔음.
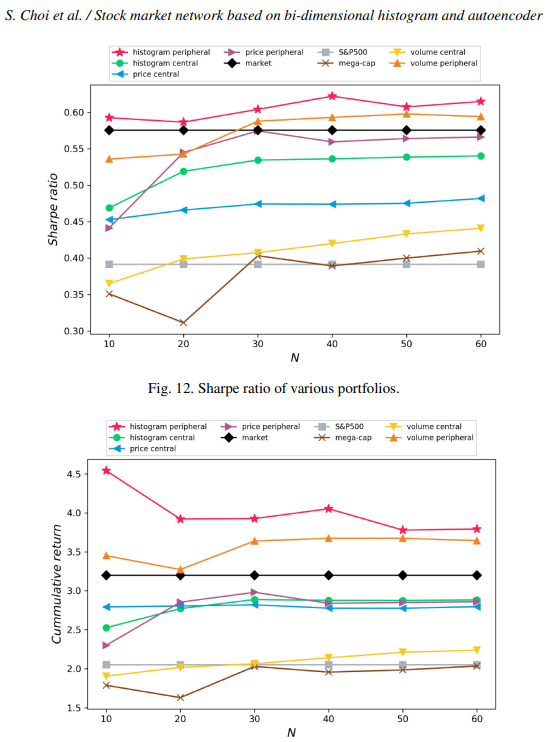
위의 그래프를 보면, 히스토그램 네트워크(histogram network)의 주변 노드(peripheral nodes)로 구성한 포트폴리오의 sharpe ratio가 제일 높은 것을 볼 수 있다. 또한, 'mega-cap'을 제외한 포트폴리오들은 S&P 500 종목으로 구성된 포트폴리오보다 더 나은 sharpe ratio를 보임.
누적 수익률도 히스토그램 네트워크의 주변노드를 사용한 것이 중심노드를 사용한 것보다 높음.
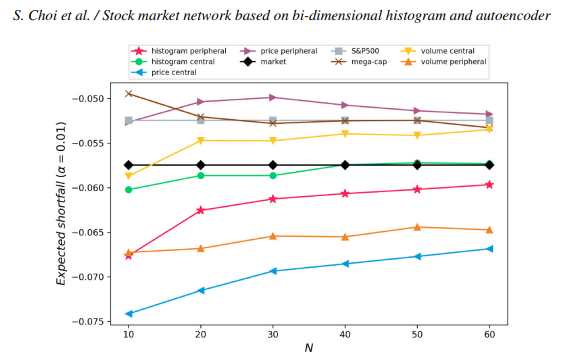
다만, 미달 위험(shortfall risk)은 히스토그램 네트워크(histogram network)의 주변노드(peripheral nodes)로 구성된 포트폴리오가 다른 포트폴리오들에 비해서 없는 편은 아닌 것으로 보임.
결과적으로 히스토그램 네트워크의 주변노드로 구성된 포트폴리오는 sharpe ratio와 cumulative return에서는 좋은 퍼포먼스를 보이고, shortfall 측면에서는 평범한 수준.
5. Conclusion
최종적으로 이 논문을 요약하자면,
- S&P 500 상위 400개의 종목들의 주가, 거래량 데이터로 구성되어 있고 이를 이용해 2D 히스토그램 제작, 오토인코더를 이용하여 이를 차원 축소하여 유의미한 특징(feature)을 추출. 이를 이용해 network를 구성함
- 히스토그램 분산도가 보통보다 높거나 낮은 주식들은 히스토그램 네트워크의 주변부(가장자리)에 위치하고, 분산도가 보통 수준인 주식들은 중심부에 위치함
- 히스토그램 네트워크(histogram network)와 주가 네트워크(price network)를 비교했을 때, 히스토그램 네트워크를 이용하여 구성한 포트폴리오의 퍼포먼스가 좋고, 중심노드(central nodes)보다는 주변노드(peripheral nodes)로 포트폴리오를 구성해야 퍼포먼스가 좋다. 즉, 히스토그램 네트워크의 주변노드로 구성한 포트폴리오의 퍼포먼스가 좋음
Contents
소중한 공감 감사합니다